Pandas的crosstab函数( 三 )
如你所见 , 即使使用unstack()链接 , groupby()也比其他两个快3倍 。 这说明如果你只想分组和计算摘要统计信息 , 那么应该使用相同的groupby() 。 当我链接其他方法(如simple round()时 , 速度差甚至更大 。
其余的比较主要是关于pivot_table()和crosstab() 。 如你所见 , 这两个函数的结果的形状是相同的 。 两者之间的第一个区别是crosstab()可以处理任何数据类型 。
它可以接受任何类似数组的对象 , 比如列表、numpy数组、数据帧列(pandas series) 。 但是 , pivot_table()只对dataframe有效 。 在一个很有帮助的StackOverflow中 , 我发现如果在数据帧上使用crosstab() , 它会在后台调用pivot_table() 。
接下来是参数 。 有些参数只存在于一个参数中 , 反之亦然 。 第一个最流行的是crosstab()的normalize 。 normalize接受以下选项(来自文档):
- 如果传递了all或True , 则将规范化所有值 。
- 如果传递index , 将规范化每一行 。
- 如果传递columns , 将规范化每个列 。
cross = pd.crosstab(index=diamonds['cut'],columns=diamonds['color'],normalize='all')plot_heatmap(cross, fmt='.2%')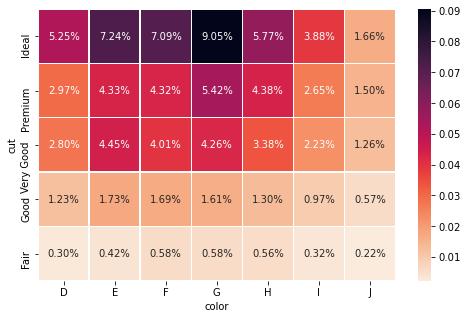 文章插图
文章插图如果传递all , 对于每个单元格 , pandas计算总金额的百分比:
# 证明所有值加起来约等于1>>> pd.crosstab(diamonds['cut'],diamonds['color'],normalize='all').values.sum()1.0000000000000002如果传递index或columns , 则按列或按行执行相同的操作:cross = pd.crosstab(diamonds['cut'],diamonds['color'],normalize='index')plot_heatmap(cross, fmt='.2%')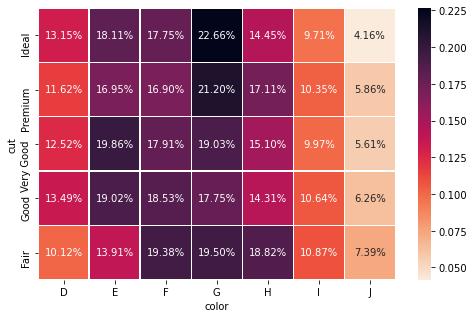 文章插图
文章插图以上是按行规范化
cross = pd.crosstab(diamonds['cut'], diamonds['color'], normalize='columns')plot_heatmap(cross, fmt='.2%')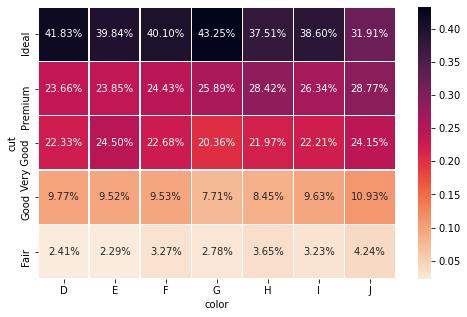 文章插图
文章插图以上是按列规范化
在crosstab()中 , 还可以使用行名和列名直接在函数内更改索引和列名 。 之后不必手动执行 。 当我们一次按多个变量分组时 , 这两个参数非常有用 , 你将在后面看到 。
参数fill_value只存在于pivot_table()中 。 有时 , 当你按许多变量分组时 , 不可避免地会出现不一致 。 在pivot_table()中 , 可以使用fill_value将它们更改为自定义值:
diamonds.pivot_table(index='color',columns='cut',fill_value=http://kandian.youth.cn/index/0)但是 , 如果使用crosstab() , 则可以通过在dataframe上链接fillna()来实现相同的效果:pd.crosstab(diamonds['cut'], diamonds['color']).fillna(0)Pandas crosstab()的进一步定制crosstab()的另外两个有用参数是margins和margins_name(两者都存在于pivot_table()中) 。 设置为True时 , 边界计算每行和每列的和 。 我们来看一个例子:pd.crosstab(index=diamonds['cut'],columns=diamonds['clarity'],margins=True)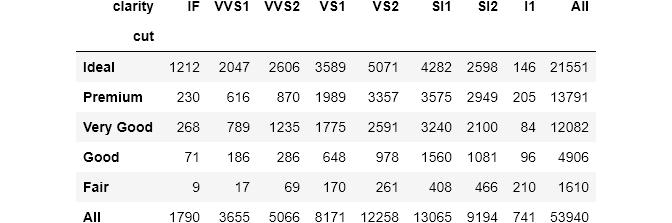 文章插图
文章插图pandas自动添加最后一行和最后一列 , 默认名称为All 。 margins_name可以控制名字:
pd.crosstab(index=diamonds['cut'],columns=diamonds['clarity'],margins=True,margins_name='Total Number')
- 不常见的Pandas小窍门:我打赌一定有你不知道的
- countif函数的四种另类经典用法,我不说没人告诉你
- Pandas的SettingWithCopyWarning
- 让人头痛的Generator 函数的异步应用真的有用吗?
- PowerQuery 表达式计算函中调用其他函数的方法
- Python中文速查表-Pandas 基础
- Pandas教程