Python爬虫案例:爬取必应壁纸
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 。
以下文章来源于 incipe, 作者 incipe
 文章插图
文章插图
前言一个喜欢折腾的人 , 长期看到桌面只有一种壁纸 , 就想着自己从网上爬取一些壁纸 , 存下来 , 随机切换壁纸 。
工具Python3 + requests + re
Fiddler 抓包工具 。
 文章插图
文章插图
分析必应官网好像无法使用 Ctrl + U 查看源代码和 Ctrl + Shift + I或者F12 打开控制台 。
通过 Fiddler 进行抓包 。
发现就这两个请求
 文章插图
文章插图
那么可以肯定 , 图片的 url 肯定就在网页源代码里面 。
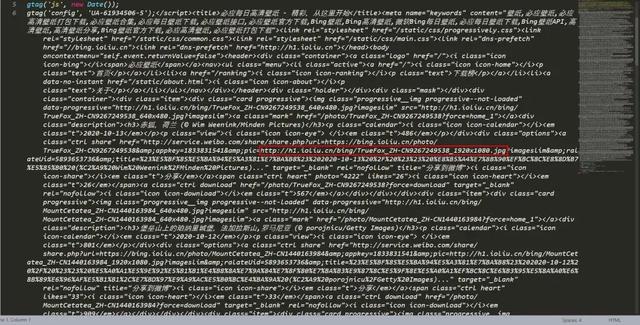 文章插图
文章插图
我们可以在源代码中看到我们想要的图片 url
通过正则进行抓取即可 。
import requestsimport threadingimport jsonimport refrom pprint import pprintimport timeclass Bing:def __init__(self):self.url = "{}"self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"}def parse_url(self, url):print("*" * 20)response = requests.get(url, headers=self.headers)return response.contentdef regular_img_name(self, img_url):ret = re.findall(r"(.*?)\.(.*?)$", img_url, re.M | re.S)print(ret)return retdef download_imgs(self, img_list):for url in img_list:img = self.parse_url(url)time.sleep(1)strs = self.regular_img_name(url)with open("./bing/{}.{}".format(strs[0][0], strs[0][1]), "wb") as f:f.write(img)print("{} success".format(url))def regular_img_url(self, html_str):ret = re.findall(r".*?pic=(.*?)\?imageslim.*?", html_str, re.M | re.S)return retdef run(self):for i in range(1, 10):url = self.url.format(i)html_str = self.parse_url(url).decode()img_list = self.regular_img_url(html_str)print(img_list)self.download_imgs(img_list)if __name__ == "__main__":bing = Bing()bing.run()【Python爬虫案例:爬取必应壁纸】可以改进为多线程爬虫版本~
总结写完代码后发现:
必应壁纸好像提供了官方接口的~
;n=1只要在解析出的 url 前面加上
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 2021年Java和Python的应用趋势会有什么变化?
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手
- 用Python制作图片验证码,这三行代码完事儿
- 历时 1 个月,做了 10 个 Python 可视化动图,用心且精美...
- 为何在人工智能研发领域Python应用比较多
- 对于非计算机专业的同学来说,该选择学习Python还是C
- 学习完Python之后,如何向人工智能领域发展
- 大数据专业本科生选择主攻Python语言,如何提升就业竞争力