利用Python爬虫实现vip电影下载( 二 )
2.制作表单 , 获取了vkey后 , 我们就可以制作提交post请求的表单了 , 代码很简单 , 就不做介绍了 。
datas = make_dataform(parsed_url,vkey)def make_dataform(parsed_url,vkey):datas = {'url':parsed_url,'wap':'0','ios':'0','vkey':vkey,'type':''}return datas3.发送post请求 , 这里再次说明 , 由于我原来post请求返回的信息是电影下载地址 , 所以我获得的url是下载地址 , 现在再提交post请求获得的是m3u8文件 。
download_url = post(sess,datas)def post(sess,datas):response = sess.post(api_url,headers=headers2,data=http://kandian.youth.cn/index/datas)response.encoding=response.apparent_encodingu = json.loads(response.text)return u['url']4.下载电影,由于链接不同 , 我就把我下载电影的代码放到这里 , 做个参考 。
down_load(sess,download_url)def down_load(sess,download_url):print("正在准备下载电影")response = requests.get(download_url,headers=headers2,verify=False)total_size = response.headers['Content-Length']print("将要下载的电影大小:{}MB".format(round(int(total_size)/1024/1024,2)))batch_size = int(total_size)//100#返回迭代器:是将二进制流按大小分割之后的k = input("请输入文件路径(C/D):")filename = input("请输入保存文件名:")with open(r"{}:/电影/".format(k)+filename+".mp4",'wb') as f:i = 0for content in response.iter_content(chunk_size=batch_size):f.write(content)print('\r','#'*i+'已下载{}%'.format(i),end='\r',flush=True)i += 1print("下载成功")程序界面使用PyQt5将上面的代码包装起来 , 使其更加美观 , 并添加一些功能 , 由于WebEngineView已经不能播放flash了 , 并且有些需要新建标签的链接打不开 , 所以中间的浏览器很鸡肋 , 就图个好看吧 。
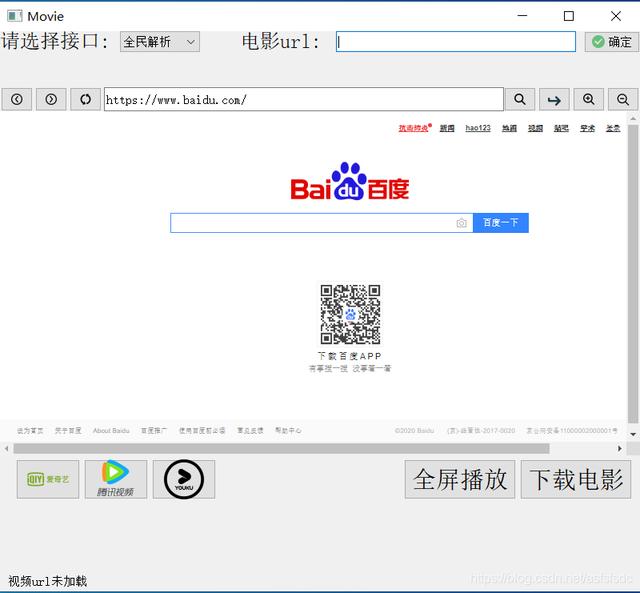 文章插图
文章插图
?这里就不详细讲了 , PyQt5也比较简单 , 容易上手 , 如果需要的话联系我吧 。
总结【利用Python爬虫实现vip电影下载】这是我第一次写博客 , 如果哪里有问题请及时指出来 , 欢迎大家指正错误 , 此爬虫项目只用于入门 , 请不要用其盈利 。 否则 , 后果自负!
- TikTok推出首个利用iPhone 12 Pro LiDAR技术的AR特效
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- Lip Factory利用人工智能现场为顾客创建定制口红
- 屏下摄像头物理隔绝难突破 三星或利用AI提升画质
- 2021年Java和Python的应用趋势会有什么变化?
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手
- 用Python制作图片验证码,这三行代码完事儿
- 历时 1 个月,做了 10 个 Python 可视化动图,用心且精美...