Python爬虫采集网易云音乐热评实战( 二 )
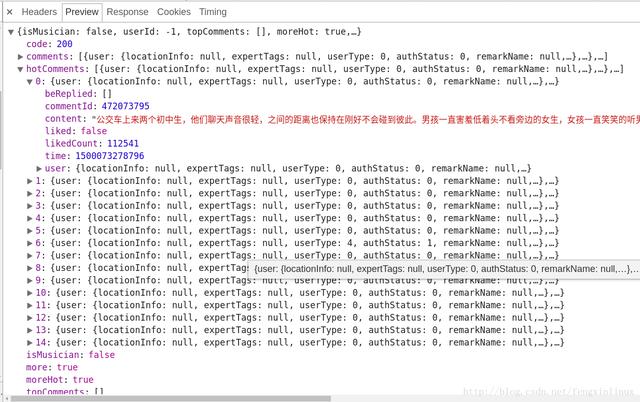
服务器返回的和评论相关的数据为json格式的 , 里面含有非常丰富的信息(比如有关评论者的信息 , 评论日期 , 点赞数 , 评论内容等等) , 其中hotComments就是我们要找的热门评论 , 总共15条 , 如图所示:
 文章插图
文章插图
?
至此 , 我们已经确定了方向了 , 即只需要确定params和encSecKey这两个参数值即可 。 但是这两个参数是经过特定的算法进行加密的 , 怎么办呢?我发现了一个规律 , 中 R_SO_4_后面的数字就是这首歌的id值 , 而对于不同的歌曲的param和encSecKey值 , 如果把一首歌比如A的这两个参数值传给B这首歌 , 那么对于相同的页数 , 这种参数是通用的 , 即A的第一页的两个参数值传给其他任何一首歌的两个参数 , 都可以获得相应歌曲的第一页的评论 , 对于第二页 , 第三页等也是类似 。 而我们其实只需要获取第一页的15条热门评论 , 所以我们只需要随便找一首歌 , 将这首歌第一页中的该请求中的params和encSecKey这两个参数值复制下来 , 就可以使用了 。 关于这两个参数如何解密 , 强大的知乎上其实已经有答案的了 , 感兴趣的朋友可以进去看一下() , 我们在这里就只需要用我们这种偷懒的办法就可以完成需求了 , xixi 。
到此为止 , 我们如何抓取网易云音乐的热门评论已经分析完了 , 我们再分析一下如何获取云音乐热歌榜中所有歌曲的信息 。
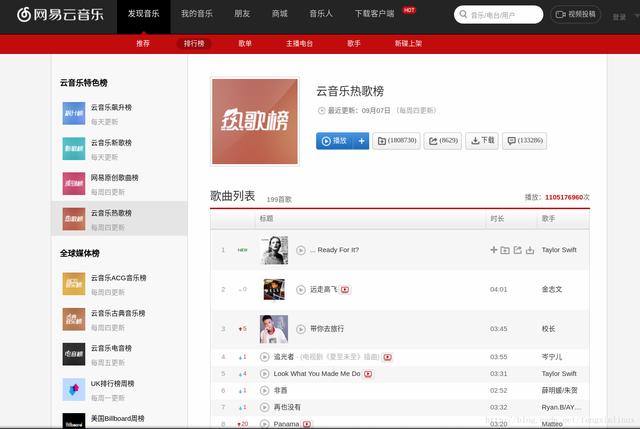
我们需要获取云音乐热歌榜中的所有歌曲的歌曲名和对应的id值 。 跟上面的分析步骤类似 , 我们先进入热歌榜的网址 , 如图:
 文章插图
文章插图
?
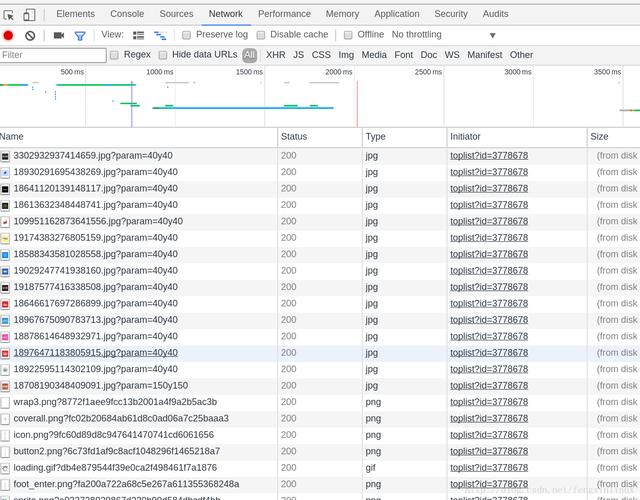
按F12 , 进入WEB工作台 , 如图:
 文章插图
文章插图
?
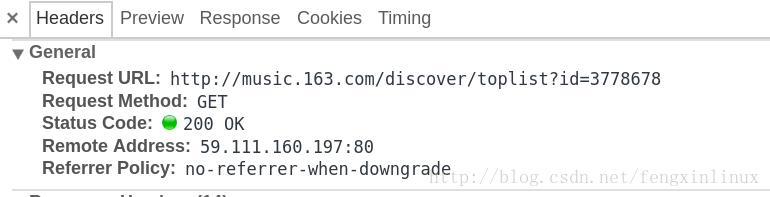
我们在一个名为toplist?id=3778678的GET请求中 , 找到了该榜单的所有歌曲信息 。
请求对应的信息如图:
 文章插图
文章插图
?
我们预览一下该请求返回的结果 , 如图:
 文章插图
文章插图
?
我们在代码的第524行我们找到了包含歌曲信息的代码 , 如图:
 文章插图
文章插图
?
因此 , 我们只需要将该请求的代码中 , 将包含信息的代码筛选出来 。 我们在这里使用正则表达式进行数据筛选 。 通过观察特点 , 我们可以通过两次正则表达式的筛选 , 将我们需要的歌曲信息提取出来 。 第一次正则表达式我们将该请求返回的所有代码中 , 提取出第525行代码 。 第一次正则表达式如下:
- .*
第二次正则表达式我们将该第524行中我们需要的歌曲信息提取出来 , 我们需要歌曲的歌名和id , 对应的正则表达式如下:获取歌名:
到此 , 我们整个过程已经分析完了 , 上代码看具体细节~~代码如下:
#!/usr/bin/env python3# -*- coding: utf-8 -*-import reimport urllib.requestimport urllib.errorimport urllib.parseimport jsondef get_all_hotSong():#获取热歌榜所有歌曲名称和idurl=''#网易云云音乐热歌榜urlheader={#请求头部'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}request=urllib.request.Request(url=url, headers=header)html=urllib.request.urlopen(request).read().decode('utf8')#打开urlhtml=str(html)#转换成strpat1=r'
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 2021年Java和Python的应用趋势会有什么变化?
- 非计算机专业的本科生,想利用寒假学习Python,该怎么入手
- 用Python制作图片验证码,这三行代码完事儿
- 历时 1 个月,做了 10 个 Python 可视化动图,用心且精美...
- 为何在人工智能研发领域Python应用比较多
- 对于非计算机专业的同学来说,该选择学习Python还是C
- 学习完Python之后,如何向人工智能领域发展
- 大数据专业本科生选择主攻Python语言,如何提升就业竞争力