随机森林(Random Forest)算法原理
一、随机森林算法简介:在机器学习中 , 随机森林是一个包含多个决策树的分类器 , 并且其输出的类别是由个别树输出的类别的众数而定 。Leo Breiman和Adele Cutler发展出推论出随机森林的算法 。 而 "RandomForests" 是他们的商标 。 这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decisionforests)而来的 。 这个方法则是结合Breimans 的 "Bootstrapaggregating" 想法和 Ho的"randomsubspacemethod"以建造决策树的集合 。
基于树分类器的集成算法(Ensemble Learning) , 其包含了2种十分有效地机器学习技术:Bagging和随机变量选择 , 随机森林它属于Bagging类型 , 通过组合多个弱分类器 , 最终结果通过投票或取均值 , 使得整体模型的结果具有较高的精确度和泛化性能 。 其可以取得不错成绩 , 主要归功于“随机”和“森林” , 一个使它具有抗过拟合能力 , 一个使它更加精准 。
集成学习(ensemble)思想是为了解决单个模型或者某一组参数的模型所固有的缺陷 , 从而整合起更多的模型 , 取长补短 , 避免局限性 。 随机森林就是集成学习思想下的产物 , 将许多棵决策树整合成森林 , 并合起来用来预测最终结果 。
 文章插图
文章插图
二、随机森林的特点(1)优点l在当前所有的算法中 , 具有极好的准确率 , 与其他算法相比有很大优势 。
l训练速度快 , 容易做成并行化方法 , 且在训练过程中能够检测到特征之间的影响 。
l随机森林能够评估那些特征比较重要 。
l随机森林有很强的抗干扰能力
l对于不平衡数据集来说 , 随机森林可以平衡误差 。
l……
(2)缺点l随机森林在解决回归问题时 , 并没有像它在分类中表现那么好 , 因为它并不能给出一个连续的输出 。
l随机森林对于统计建模者来说 , 就像一个黑盒子 , 无法控制模型内部的运行 。
l可能有很多相似的决策树 , 掩盖了真实的结果 。
l执行数据虽然比boosting等快(随机森林属于bagging),但比单只决策树慢得多 。
三、随机森林如何构建(1) 数据的随机性选取
(2) 待选特征的随机选取
四、随机森林在中药指纹图谱中的应用随着数据的复杂性不断增加 , 一些更先进的机器学习方法 , 如支持向量机(SVM)、随机森林(RF)、核主成分分析(KPCA)等越来越多地用于相关数据分析 。 其中 , 随机森林作为一种分类和预测模型 , 在许多领域取得了广泛的应用 。 随机森林算法凭借其精度高、适用性广、非线性数据分析能力强、不易过拟合等优势 , 成为近年来生物医学及生物信息学十分热门的前沿研究领域之一 。
目前为止 , 很少的文献报道随机森林方法在中药指纹图谱中的应用 。 因此 , 以夏桑菊颗粒HPLC指纹图谱为例 , 结合高效液相色谱法与不同化学计量学方法对不同品牌夏桑菊颗粒的差异进行研究 , 采用高效液相色谱法建立不同品牌夏桑菊颗粒的指纹图谱 , 进而将得到的指纹图谱数据作为特征向量分别输入主成分分析、最小偏二乘法判别分析、随机森林等计量学方法 , 比较随机森林算法在色谱分析中的优势 , 以期得到中药指纹图谱分析的新的有效手段和方法 。
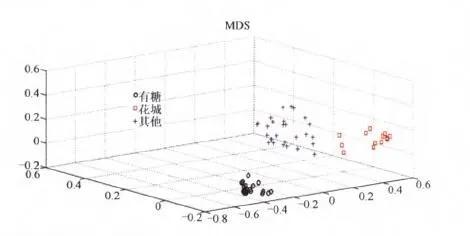
用随机森林算法对3类夏桑菊产品进行分析 。 随机森林是一类基于分类回归树集成算法 , 其在进行数据聚类分析的同时还能够得到各变量(在本文中即为各色谱峰或色谱峰所代表的物质)对于聚类的贡献度 。 每个物质的聚类分析结果见下图 , 可见3类夏桑菊产品均得到有效的区分 。 星群(有糖型)夏桑菊处于其他2类的另一个方向 , 而花城和其他类夏桑菊产品虽然距离较近 , 说明2类产品还是较为相似 , 但依然存在区别 , 在随机森林算法中均得到有效区分 。
 文章插图
文章插图
- 蚂蚁森林推出4年时间了,如今种了多少树,沙漠又变成啥样了?
- 支付宝打造的天价蚂蚁森林,四年时间过去了,现在长成什么样了?
- 小米11产品包装中将取消随机附送充电器
- 手机行业取消随机附赠充电器争议不断 小米或成破局者
- 跟风苹果?小米11将取消随机附送充电器 网友调侃:不愧是雷布斯
- 雷军响应库克号召?小米11取消随机附送充电器,你能接受吗?
- 雷军:为环保,小米11取消随机附送充电器,希望大家支持
- 引入原字节跳动高管柳甄,元气森林要加快出海
- 原字节跳动高管柳甄加入元气森林 负责海外业务
- 突发!联想集团创始人柳传志侄女柳甄加盟元气森林,负责海外业务,曾是Uber中国区战略负责人