Lock、Synchronized锁区别解析( 三 )
上下文切换:线程之间的切换需要前一个线程先保存当前的状态 , 然后进入 "睡眠" 状态 , 然后下一个线程 "启动" , 执行 , 等到下一次前一个线程获取到 CPU 调度时 , 再去读取上次保存的状态 , 然后 "启动" 。 我们把一个线程从保存当前状态到下一次"启动"完成称作这个线程的一次 "上下文切换" 。
synchronized 锁升级机制是从偏向锁->轻量级锁->重量级锁, 这个过程是不可逆的 。
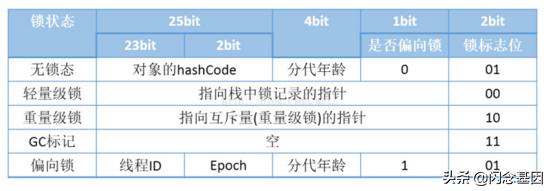
在具体说这三种锁时 , 先要了解对象头的 Mark Word 部分 , 我们都知道对象上存储着这个对象的一切信息 , 包括它的地址、内部方法、属性等信息 , 前面说过监视器 , 就是一个锁对应着一个对象 , 所以在对象上也存储着这个对象所关联锁的信息 。 关于锁的信息就存储在对象对象头的 Mark Word 部分上 。 下面是 Mark Word 结构示意图:
 文章插图
文章插图
下面说得偏向锁、轻量级锁、重量级锁都会用到这上面的字段 。
1、偏向锁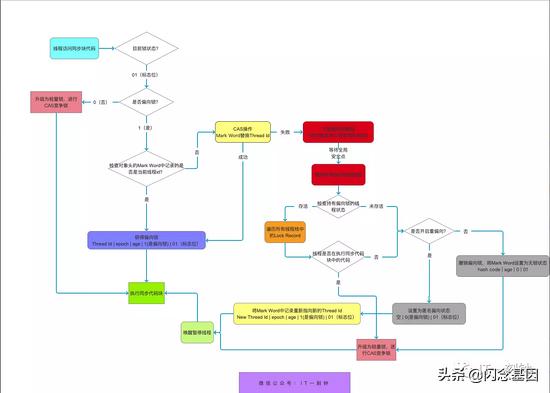 文章插图
文章插图
首先是偏向锁 , 偏向锁是指一段代码同一时间内只有一个线程执行(这是在开启了重偏向 , 如果没有开启重偏向则是一段代码一直只有一个线程执行) 。 当不满足条件时就会升级成轻量级锁 。 偏向锁的执行逻辑是:
1、 判断 对象头的 Mark Word 部分的锁标志位 ,01表示为偏向锁 , 00轻量级锁 , 10重量级锁
2、 判断是否偏向锁
1、0 , 升级为轻量级锁 , 然后执行相关策略
2、1 , 检查线程ID位是否是当前线程ID 。
1、 是 , 获得偏向锁 , 执行代码
2、 否 , 尝试进行 CAS写入当前线程ID
1、 成功 。 获得锁 , 执行
2、 失败 。 说明已经存在线程 ID了 , 会在安全的时间点暂停当前持有该偏向锁的线程 , 然后判断该线程是否存活
1、 存活 , 判断该线程是否正在执行锁住的代码
1、 正在执行 , 升级为轻量级锁 , 然后执行轻量级锁的相关策略(为该线程的栈中开启一片区域来保存复制的 mark work 记作 lock record, 然后将锁对应的对象对象头的 mark word 部分的指针指向该线程 , 然后唤醒该线程继续执行 , 在此期间当前线程也会在栈中拷贝一份 mark word然后使用自旋锁+ CAS乐观锁尝试将该对象的 mark word 指针指向当前的 lock record, 执行完轻量级锁后 mark word 指针会删除 , 以便后面的线程重新指向)
2、 没有执行 。 检查是否开启重偏向 。
1、 开启了 , 先设置为匿名偏向状态 , 然后将 mark word 的 threadId 写入当前的线程 ID位置 , 然后再唤醒线程 , 继续执行
2、 没有开启 , 先撤销偏向锁 , 将 mark word 设置为无锁状态 , 然后升级轻量级锁 , 执行轻量级锁的执行策略
2、没有存活 , 检查是否开启重偏向 。
从上面的执行策略来看 , 偏向锁下是没有加锁、释放锁的操作的 , 这样就加快了对 某段一段时间内只有一个线程执行的代码 的执行效率 。 上面还提到自旋锁 , 乐观锁 。 这里是准备后面再开一篇多线程的博客专门来说这些 , 现在先简单说一下 。
自旋锁 :由于线程切换需要进行 "上下文切换" , 这个过程一次两次可能不算耗时 , 但是在多线程下 , 特别是在高并发场景下大量线程频繁地进行线程切换 , 就会出现大量的 "上下文切换" , 这中间消耗的时间是非常长的 , 所以对于这部分代码就使用 "自旋锁" , 它的特点是不会保存当前线程状态 , 也不会进入 "睡眠状态" , 而是一直尝试获取 CPU 调度 , 保持一种 "运行" 状态 , 这样就省去了 "上下文切换" 的时间 , 当然 , 这只适用于多核 CPU, 单核 CPU 是不能发挥 "自旋锁" 的作用的 , 因为它在一直尝试 , 这个尝试的过程也会占用 CPU。
- 华为畅享20se和红米note9哪个好区别在哪 参数对比评测
- 荣耀v40pro对比vivox60pro哪个好区别在哪 性能谁更强
- realmev15和realmev3区别参数对比 哪个好性价比高
- 红米k40pro和荣耀30区别哪个好 不同点对比参数配置谁好
- iqoo7和红米k30至尊纪念版哪个好区别在哪 参数对比评测
- 小米11和红米k30pro哪个好性价比高 参数配置对比区别
- 华为nova8与小米10对比哪个好 参数配置区别性能评测
- 「小狮子诊所」游戏耳机和音乐耳机究竟有什么区别?
- 荣耀v40和华为p40对比哪个好 参数配置区别性能谁更强
- 小米11和华为p40pro哪个好区别在哪 参数优缺点对比评测