Sharding-Jdbc之水平分库和读写分离(二)
欢迎关注头条号:老顾聊技术
精品原创技术分享 , 知识的组装工
前言前几天老顾与小伙伴们分享了sharding-jdbc的水平分表功能 , 今天我们继续分享一些水平分库 , 以及读写分离的功能 , 以及如何解决读写延迟问题 。 小伙伴就继续往下看吧 。
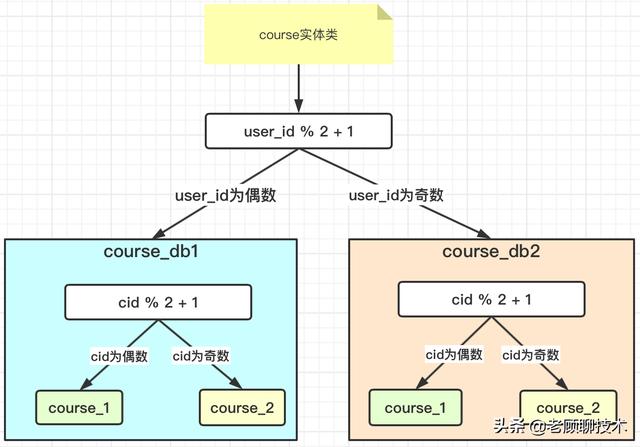
分库分表业务需求分片规则在做分库分表时 , 首先要定义好我们的分片规则 , 从业务逻辑上面要思路清晰 。 我们基于上一篇文章的案例 , 继续进行分库:
分库规则:根据用户user_id为偶数时将数据添加到course_db1中;为奇数时将数据添加到course_db2中 。
分表规则:根据课程cid为偶数时将数据添加到course_1中;为奇数时将数据添加到course_2中
 文章插图
文章插图
创建数据库创建数据库以及表 , 和上一篇文章的一样 。
 文章插图
文章插图
配置分片我们在基于上一篇的配置文件中 , 进行分库的需求改造
定义数据源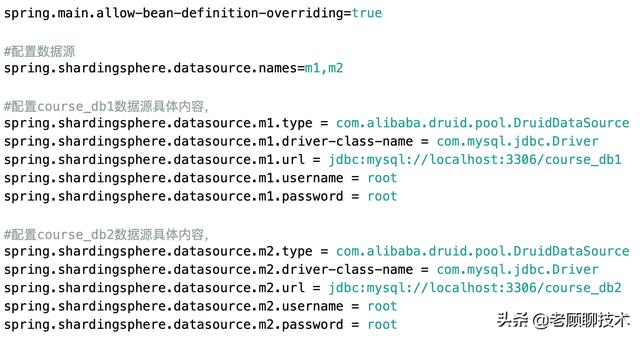 文章插图
文章插图
上图的配置就是配置了2个数据库源 , 并定义名称m1、m2 。
分布节点 文章插图
文章插图
上面重新定义了course逻辑表的真实的分布节点 , 根据表达式course分布在m1、m2数据库中 , 并且表名为course_1、course_2
分库规则 文章插图
文章插图
上面在原来的基础上面 , 增加了分库的策略规则 。 分片配置就此结束 。
改造测试代码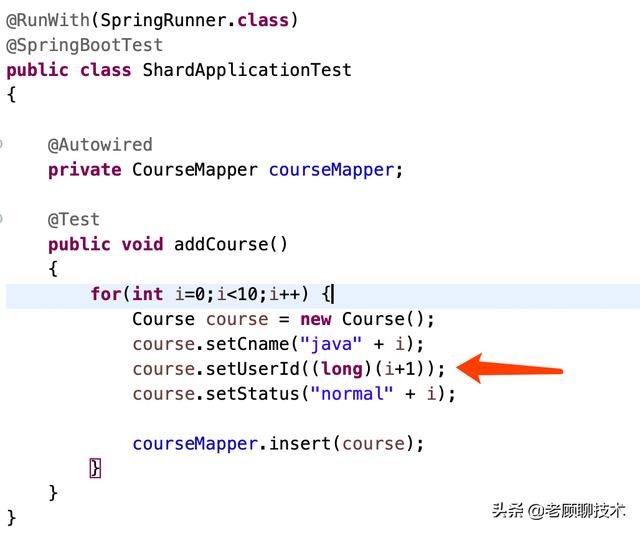 文章插图
文章插图
测试代码对userId进行了改造 。
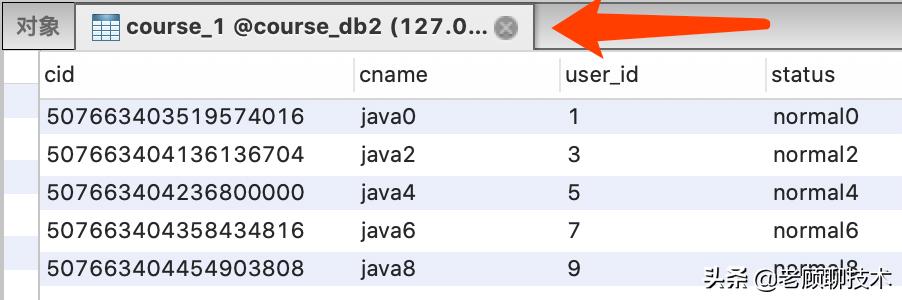
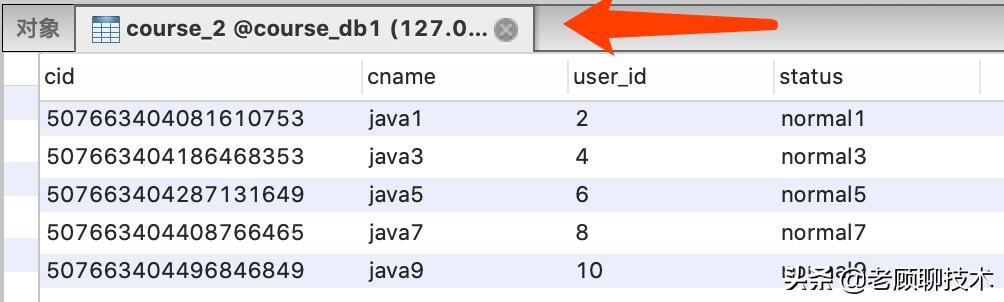
执行测试我们可以看到执行日志 , 符合我们之前定义的分片策略
 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
读写分离概念一般熟知 Mysql 数据库的朋友知道 , 当表的数据量达到千万级时 , SQL 查询会逐渐变的缓慢起来 , 往往会成为一个系统的瓶颈所在 。 为了提升程序的性能 , 除了在表字段建立索引(如主键索引、唯一索引、普通索引等)、优化程序代码以及 SQL 语句等常规手段外 , 利用数据库主从读写分离(Master/Slave)架构:
就是为了缓解数据库压力 , 将写入和读取操作分离为不同数据源 , 写库称为主库 , 读库称为从库 , 一主库可配置多从库 。
 文章插图
文章插图
【Sharding-Jdbc之水平分库和读写分离(二)】上图所表达的:读都落在从库 , 写落在主库
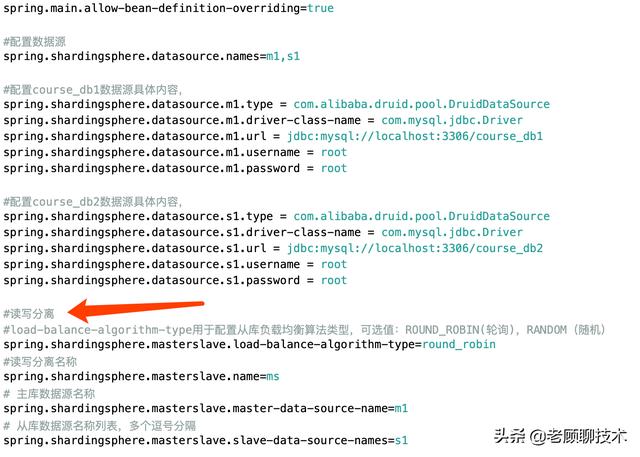
读写分离配置mysql的主从配置 , 这里老顾就不讲了 , 小伙伴们可以去上网查看 。 我们这里就给出读写分离的配置
 文章插图
文章插图
上面的spring.shardingsphere.masterslave是核心配置 , 配置还是相对简单的 。
select查询代码测试 , 走的是slave库
[ main] ShardingSphere-SQL : Rule Type: master-slave[ main] ShardingSphere-SQL : SQL: SELECTcid,cname,userId,statusFROM course ::: DataSources: slave
- Keep能一直“keep”吗?
- 腾讯晋升首位17级杰出科学家 史上最高水平
- RedmiBook Pro 15S现身跑分库:11代酷睿H35+Ryzen显卡
- 努比亚红魔6现身跑分库:骁龙888+8GB内存
- 2020年全球笔记本库存量达到自iPhone问世以来的最高水平
- 撇开被罚80万一事来谈,杜蕾斯蹭苹果5G热点的海报水平怎样?
- 多个你不知道的 CSS 居中方案
- 5G基站辐射到底有无影响?中国辐射标准与美日相比处于什么水平
- 印度最大的塔塔集团,年营收6636亿,放在中国是什么水平?
- 三星note20ultra正名,9999元只是它该有的水平