Python高级技巧:用一行代码减少一半内存占用( 二 )
我们分别得到460和484字节 , 这似乎更接近事实 。
使用这个函数 , 我们可以进行一系列实验 。 例如 , 我想知道如果DataItem放在列表中 , 数据将占用多少空间 。
get_size([d1])函数返回532个字节 , 显然 , 这些是“原本的”460+一些额外开销 。 但是get_size([d1 , d2])返回863个字节—小于460+484 。 get_size([d1 , d2 , d1])的结果更加有趣 , 它产生了871个字节 , 只是稍微多了一点 , 这说明Python很聪明 , 不会再为同一个对象分配内存 。
现在我们来看问题的第二部分 。
是否有可能减少内存消耗?
答案是肯定的 。 Python是一个解释器 , 我们可以随时扩展我们的类 , 例如 , 添加一个新字段:
d1 = DataItem("Alex", 42, "-")print ("get_size(d1):", get_size(d1))d1.weight = 66print ("get_size(d1):", get_size(d1))这是一个很棒的特点 , 但是如果我们不需要这个功能 , 我们可以强制解释器使用slots指令来指定类属性列表:
class DataItem(object):__slots__ = ['name', 'age', 'address']def __init__(self, name, age, address):self.name = nameself.age = ageself.address = address更多信息可以参考文档中的“dict和weakref的部分 。 使用dict所节省的空间可能会很大” 。
我们尝试后发现:get_size(d1)返回的是64字节 , 对比460直接 , 减少约7倍 。 作为奖励 , 对象的创建速度提高了约20%(请参阅文章的第一个屏幕截图) 。
真正使用如此大的内存增益不会导致其他开销成本 。 只需添加元素即可创建100,000个数组 , 并查看内存消耗:
data = http://kandian.youth.cn/index/for p in range(100000):data.append(DataItem("Alex", 42, "middle of nowhere"))snapshot = tracemalloc.take_snapshottop_stats = snapshot.statistics('lineno')total = sum(stat.size for stat in top_stats)print("Total allocated size: %.1f MB" % (total / (1024*1024)))在没有slots的情况结果为16.8MB , 而使用slots时为6.9MB 。 当然不是7倍 , 但考虑到代码变化很小 , 它的表现依然出色 。
现在讨论一下这种方式的缺点 。 激活slots会禁止创建其他所有元素 , 包括dict , 这意味着 , 例如 , 下面这种将结构转换为json的代码将不起作用:
def toJSON(self):return json.dumps(self.__dict__)但这也很容易搞定 , 可以通过编程方式生成你的dict , 遍历循环中的所有元素:
def toJSON(self):data = http://kandian.youth.cn/index/dictfor var in self.__slots__:data[var] = getattr(self, var)return json.dumps(data)向类中动态添加新变量也是不可能的 , 但在我们的项目里 , 这不是必需的 。
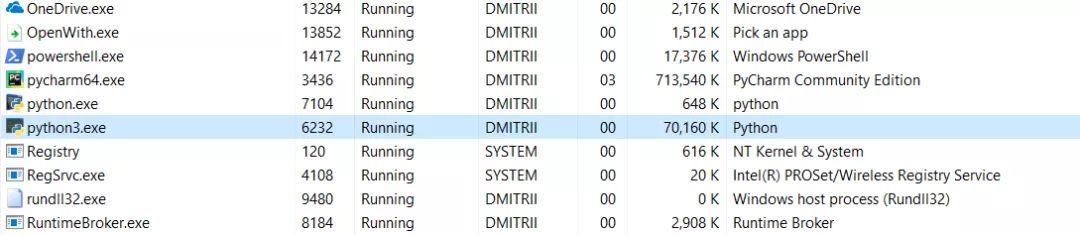
下面是最后一个小测试 。 来看看整个程序需要多少内存 。 在程序末尾添加一个无限循环 , 使其持续运行 , 并查看Windows任务管理器中的内存消耗 。
没有slots时
 文章插图
文章插图
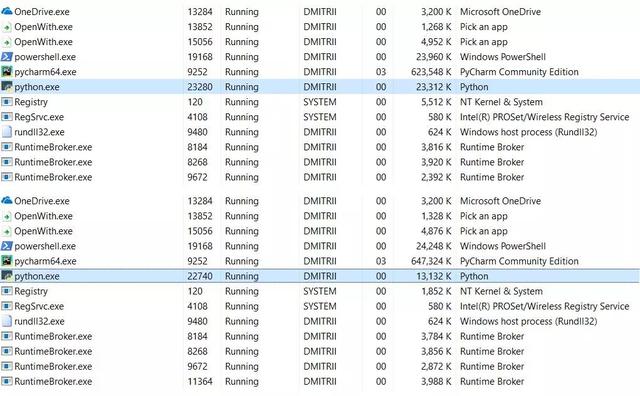
69Mb变成27Mb……好吧 , 毕竟我们节省了内存 。 对于只添加一行代码的结果来说已经很好了 。
注意:tracemalloc调试库使用了大量额外的内存 。 显然 , 它为每个创建的对象添加了额外的元素 。 如果你将其关闭 , 总内存消耗将会少得多 , 截图显示了2个选项:
 文章插图
文章插图
如何节省更多的内存?
可以使用numpy库 , 它允许你以C风格创建结构 , 但在这个的项目中 , 它需要更深入地改进代码 , 所以对我来说第一种方法就足够了 。
- 教你点开微信右上角,除了看街景知道哪儿人多,还隐藏5个技巧
- 大一上学期学了Python,希望主攻大数据还应该学习什么语言
- 从运维岗转向开发岗,该选择学习Java还是Python
- 「听」上海有望诞生首位快递工程高级工程师
- 你真的会用华为手机吗?10个EMUI使用技巧,你未必全知道
- 点赞!上海评出首位快递高级工程师
- 上海评出首位快递高级工程师
- 手机内存不足别乱删,学会这5个技巧,让手机释放大量空间
- 计算机专业大一下学期,该选择学习Java还是Python
- 华为认证HCIP-GaussDB-OLTP发布,下一个高级DBA会是你吗