一文讲透“进程、线程、协程”( 三 )
【一文讲透“进程、线程、协程”】总之 , 多进程程序安全性高 , 进程切换开销大 , 效率低;多线程程序维护成本高 , 线程切换开销小 , 效率高 。 (python的多线程是伪多线程 , 下文中将详细介绍)
什么是协程协程(Coroutine , 又称微线程)是一种比线程更加轻量级的存在 , 协程不是被操作系统内核所管理 , 而完全是由程序所控制 。 协程与线程以及进程的关系见下图所示 。
- 协程可以比作子程序 , 但执行过程中 , 子程序内部可中断 , 然后转而执行别的子程序 , 在适当的时候再返回来接着执行 。 协程之间的切换不需要涉及任何系统调用或任何阻塞调用
- 协程只在一个线程中执行 , 是子程序之间的切换 , 发生在用户态上 。 而且 , 线程的阻塞状态是由操作系统内核来完成 , 发生在内核态上 , 因此协程相比线程节省线程创建和切换的开销
- 协程中不存在同时写变量冲突 , 因此 , 也就不需要用来守卫关键区块的同步性原语 , 比如互斥锁、信号量等 , 并且不需要来自操作系统的支持 。
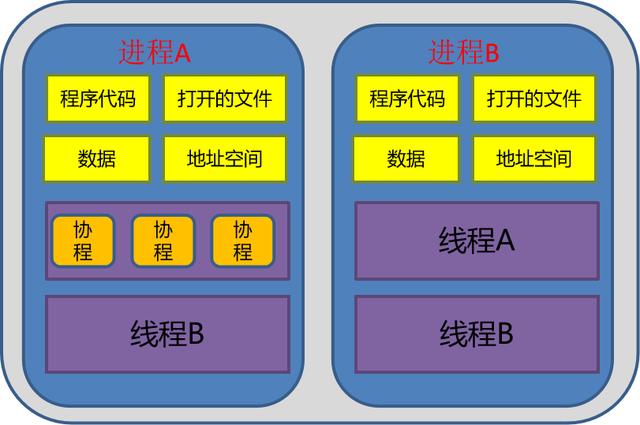 文章插图
文章插图下面 , 将针对在不同的应用场景中如何选择使用Python中的进程 , 线程 , 协程进行分析 。
如何选择?在针对不同的场景对比三者的区别之前 , 首先需要介绍一下python的多线程(一直被程序员所诟病 , 认为是"假的"多线程) 。
那为什么认为Python中的多线程是“伪”多线程呢?
更换上面multiprocessing示例中 ,
p=multiprocessing.Process(target=count,args=(i,))为p=threading.Thread(target=count,args=(i,)),其他照旧 , 运行结果如下:为了减少代码冗余和文章篇幅 , 命名和打印不规则问题请忽略
Process 0:n=5756690257,id(n)=140103573185600Process 2:n=10819616173,id(n)=140103573185600Process 1:n=11829507727,id(n)=140103573185600Process 4:n=17812587459,id(n)=140103573072912Process 3:n=14424763612,id(n)=140103573185600Main:n=17812587459,id(n)=140103573072912Total time:0.1056210994720459- n是全局变量 , Main的打印结果与线程相等 , 证明了线程之间是数据共享
什么是GILGIL来源于Python设计之初的考虑 , 为了数据安全(由于内存管理机制中采用引用计数)所做的决定 。 某个线程想要执行 , 必须先拿到 GIL 。 因此 , 可以把 GIL 看作是“通行证”,并且在一个 Python进程中 , GIL 只有一个,拿不到通行证的线程,就不允许进入 CPU 执行 。
Cpython解释器在内存管理中采用引用计数 , 当对象的引用次数为0时 , 会将对象当作垃圾进行回收 。 设想这样一种场景:
一个进程中含有两个线程 , 分别为线程0和线程1 , 两个线程全都引用对象a 。 当两个线程同时对a发生引用(并未修改 , 不需要使用同步性原语) , 就会发生同时修改对象a的引用计数器 , 造成计数器引用少于实质性的引用 , 当进行垃圾回收时 , 造成错误异常 。 因此 , 需要一把全局锁(即为GIL)来保证对象引用计数的正确性和安全性 。
- 一文看懂三星Galaxy S21系列发布会所有亮点
- 主板|主板名字带WiFi和不带有什么区别?一文读懂
- 微软发布新版Sysinternals组件Sysmon 13 可用于恶意软件进程篡改检测
- 一文读懂,书架箱和落地箱到底哪个好?
- 10nm进程受阻,芯片狂人梁孟松出走,中芯国际如何突破困境?
- 录音笔|科技解放生产力 录音笔的智能化进程
- 关闭一个进程 AMD锐龙CPU降温22.5℃
- 有史以来最大升级?一文看懂OriginOS带来的改变
- 超大杯来了!一文看懂OPPO Reno5 Pro+最大升级
- 简单一文教你制作多语言的Qlik Sense应用程序