「AI语音评测」技术简述与应用层级
编辑导语:随着科技的发展 , AI人工智能已经运用于我们的学习生活中;语音测评基于在线教育场景 , 使用语音识别、特征提取、声学模型等技术 , 提供成人和儿童的口语发音评测;本文作者分享了关于AI语音评测的技术简述与应用层级 , 我们一起来看一下 。
 文章插图
文章插图
一、前言「AI语音评测」技术 , 指的是针对口语发音水平和差错 , 进行自动评价、检错并提供指导纠正的技术 。
该技术经过几十年的发展 , 在中英文发音标准程度、口语表达能力等评测任务上已经超越了人类口语评测专家水平 , 目前该技术被普遍使用在中英文的口语评测和定级中 。
接下来我们会讨论:
- 「AI语音评测」技术简述;
- 「AI语音评测」多维度应用层级 。
音素:根据语音的自然属性划分出来的最小语音单位 。
DNN-HMM:深层神经网络-隐藏马尔科夫模型(Deep Neural Network-Hidden Markov Model) , 是目前相对流行的声学模型 。 它的出现基本替代了之前的GMM-HMM模型 。
简单的说 , 能够对音素、单词、句子、段落等多个级别的发音情况进行评价和指导反馈;测评维度包括发音准确度(音素/声调)和流利度、语调、断句、完整度等 。
使用该技术方法须满足以下条件:
- 开发前确定针对的评测语种(如英语、日语、德语等);
- 以评测语种母语者标准语音为蓝本;
- 针对评测发音特点设计评测维度;
- 针对学习者母语(如汉语)发音特点定位可能存在的缺陷 。
- 段落、句子、单词、音素多个级别维度的 , 包括语调、断句、完整度、 流利度等多个方面的指导反馈;
- 针对各个级别和维度的分项和综合得分 。
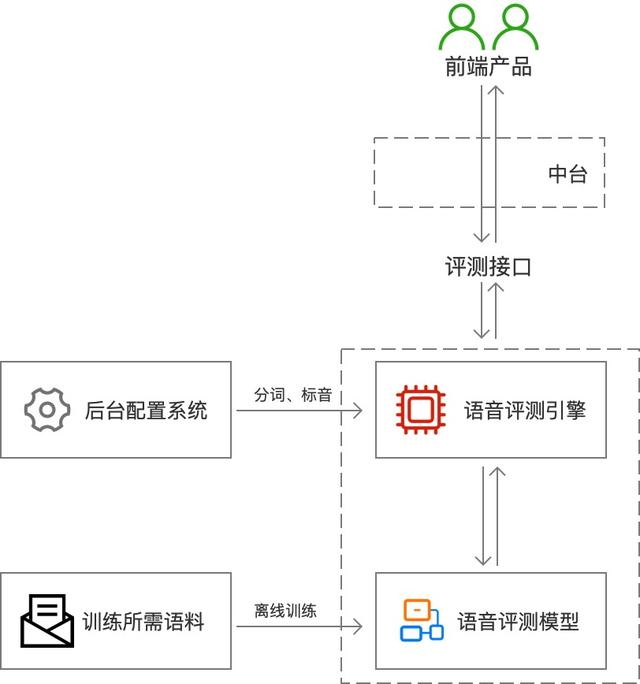 文章插图
文章插图流程:
- 用户根据给定的文本生成语音;
- 前端产品通过「评测接口」上传音频至「语音评测引擎」;
- 引擎以「语音评测模型」为基准 , 通过解码计算处理得到评测结果;
- 通过「评测接口」将评测结果返回至用户 。
- 语音评测引擎:AI评测解码和计算的核心模块 , 通过语音识别(ASR)解码转译 , 与给定的文本强制对齐 , 通过不同维度的算法得出指导反馈和评测得分 。
- 后台配置系统:语音评测前 , 需将给定的文本拆分成独立的单词或单音/音素并存储在后台配置系统中 , 为语音评测引擎提供对齐标准 。
- 语音评测模型 & 训练所需语料:使用评测引擎前 , 需使用适量的语料离线训练形成语音评测模型 , 该模型是引擎进行解码计算处理的依据 。
通过对整体架构的解读 , 我们不难发现很大部分工作都是由「AI评测引擎」完成的 , 接下来我们再简单了解一下评测引擎内部的流程和原理 。
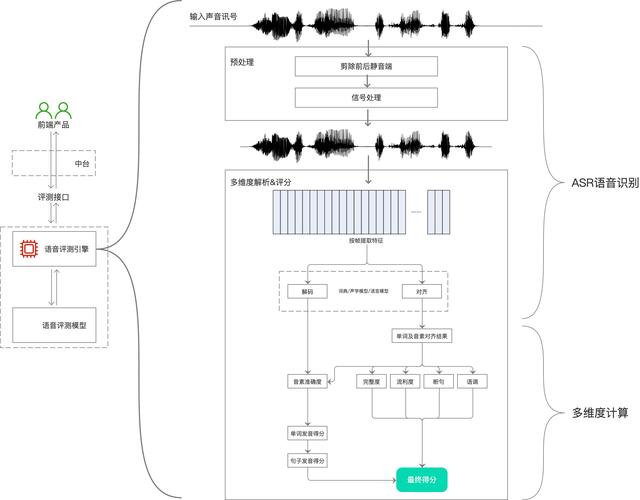 文章插图
文章插图流程:输入声音讯号→ASR语音识别→多维度算法→反馈&得分 。
输入声音讯号:通过接口将音频文件传输至后台语音评测引擎 。
语音识别(ASR):ARS(Automatic Speech Recognition)是一种将人类语音转换为文本的技术 。 在这里的作用是将上传的音频内容转换成文本 。
ASR过程是相对复杂的 , 这里简述其中几个步骤:
- 「技术」这样的思路,让控制器中按键处理数据的方法变得简单了
- Chiplet如何开拓半导体技术的未来
- 高颜值vlog语音神器,塞宾智能蓝牙麦克风评测
- 物联网相关的技术、商业生态
- 学大数据是否有前途 如何系统掌握大数据技术
- Linux培训完能到什么水平,之后还需要学习哪些技术?
- 办公游戏两不误 台电G27一体机电脑评测
- 猛犸A5新国标电瓶车评测:除了无钥匙一键启动还有更香的
- 高性能需求用户首选,LMPDA双USB-C快充线评测
- 微纳机电系统与微纳传感器技术 发展报告摘要