Python爬取lol英雄联盟全阵容皮肤
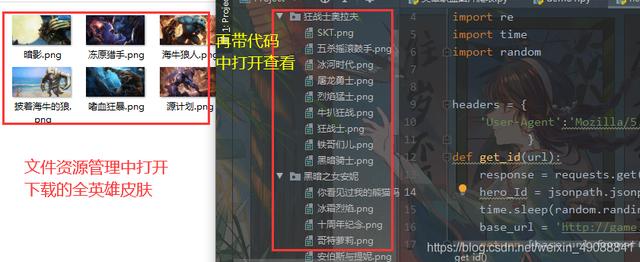
1、结果展示将每一个英雄保存一个文件夹下 , 把他所有的皮肤保存在他对应的文件夹下(自动生成的你运行爬虫就好了)
私信小编01即可获取大量Python学习资料
 文章插图
文章插图
 文章插图
文章插图
2、代码解释2.1用到第三方的模块有些自带 , 有些需要你自己安装 , pip install 模块名 就好了 , 如果有问题可以看我的第三方库导入大全那篇文章 , 有详细解释
import requests # 请求数据import os # 操作系统模块 , 用于创建文件夹import jsonpath # 用于提取json类型的数据import re # 正则表达式模块 , 用于获取皮肤名称import time # 时间模块 , 防止爬的太快被封idimport random # 随机数模块 , 配合time使用2.2请求头以及主页面js地址user-agent:故名思意 , 用户代理 , 你设置了这个相当于把爬虫程序伪装成浏览器 , 如果不设置 , 服务器就会发现你是爬虫 , 这是最基本的反爬手段之一hero_list_url:这是通过分析lol官网页面从中提取hero_id的url , 如果想学页面分析可以留言我在写一篇分析页面的文章 , 这个主要教如何爬取
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'}hero_list_url = ''2.3获得详情页面的函数【Python爬取lol英雄联盟全阵容皮肤】写一个获得hero_id的函数找到每一个英雄的详情url为下载做准备 , 这里我用了列表推导式作为返回值将所有英雄的详情url返回出来方便下载函数调用
def get_id(url):response = requests.get(url, headers=headers).json()hero_Id = jsonpath.jsonpath(response, '$..heroId')time.sleep(random.randint(1, 3))base_url = '{}.js'return [base_url.format(every_id) for every_id in hero_Id]2.4定义函数一个提取及下载数据我直接再代码中进行解释
def get_skin(li1):for url in li1: # 遍历列表推导式response = requests.get(url, headers=headers)result = response.json()['skins'] # 得到关于皮肤的所有信息skin_name = [] # 设置空列表用来存储提取到的皮肤名skin_url = [] # 设置空列表用来存储提取到的皮肤下载地址time.sleep(random.randint(1, 3)) # 随机休眠1到3秒防止被封for skin_json in result:skin_name.append(skin_json['name']) # 将英雄名保存到上面的空列表之中skin_url.append(skin_json['mainImg']) # 将英雄下载地址保存到上面的空列表之中hero_folder = 'allhero/' + response.json()['hero']['name'] + response.json()['hero']['title']#设置保存的路径if not os.path.exists(hero_folder):os.mkdir(hero_folder)# 判断路径是否存在不存在就创建一个for i in range(len(skin_url)):if not skin_url[i]=='':image_path = hero_folder +'/' + re.findall('\w+',skin_name[i])[0] + '.png' # 具体设置图片的下载路径以及名称和格式with open(image_path,'wb')as file:print('正在下载{}'.format(skin_name[i])) # 打印下载进度file.write(requests.get(skin_url[i],headers=headers).content) #下载图片3、完整代码如果遇到问题可以留言 , 我看到了就会解答 , 喜欢的话可以关注我呀 , 我基本每天都会更新有趣的东西
import requestsimport osimport jsonpathimport reimport timeimport randomheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'}def get_id(url):response = requests.get(url, headers=headers).json()hero_Id = jsonpath.jsonpath(response, '$..heroId')time.sleep(random.randint(1, 3))base_url = '{}.js'return [base_url.format(every_id) for every_id in hero_Id]def get_skin(li1):for url in li1:response = requests.get(url, headers=headers)result = response.json()['skins']skin_name = []skin_url = []time.sleep(random.randint(1, 3))for skin_json in result:skin_name.append(skin_json['name'])skin_url.append(skin_json['mainImg'])hero_folder = 'allhero/' + response.json()['hero']['name'] + response.json()['hero']['title']if not os.path.exists(hero_folder):os.mkdir(hero_folder)for i in range(len(skin_url)):if not skin_url[i] == '':image_path = hero_folder + '/' + re.findall('\w+', skin_name[i])[0] + '.png'with open(image_path, 'wb')as file:print('正在下载{}'.format(skin_name[i]))file.write(requests.get(skin_url[i], headers=headers).content)if __name__ == '__main__':hero_list_url = ''li1 = get_id(hero_list_url)get_skin(li1)
- 第2天 | 12天搞定Python,运行环境(详细步骤)
- Python高级技巧:用一行代码减少一半内存占用
- 手把手教你用python编程写一款自己的音乐下载器
- Python爬虫入门第一课:如何解析网页
- 刷爆全网的动态条形图,只需5行Python代码就能实现
- 让你的输出变得更帅,Python炫酷的颜色输出与进度条打印
- 斐波那契数列:python实现和可视化
- Python 3.9 正式发布!一图秒懂新特性
- Python解决同步验证码模拟登录问题
- 零基础小白入门必看篇:学习Python之面对对象基础