打工四年总结的数据库知识点( 六 )
 文章插图
文章插图
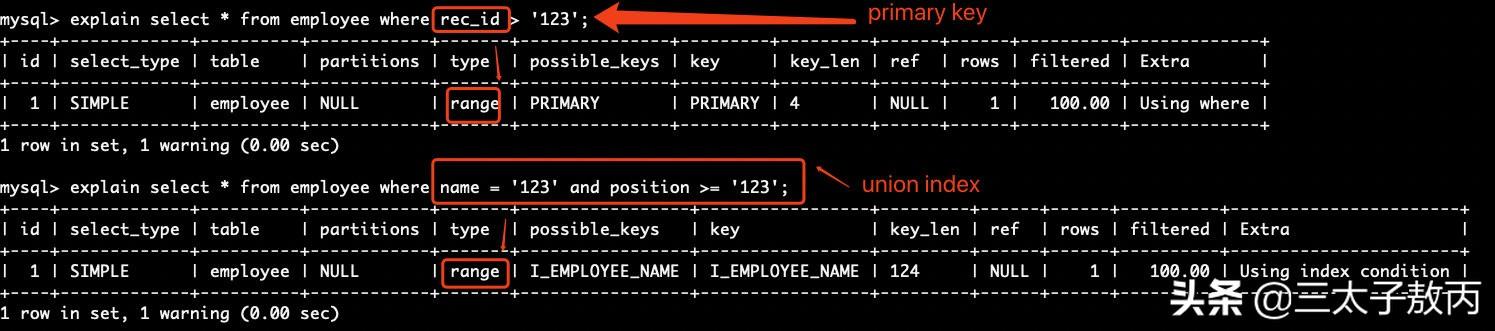
indexThe index join type is the same as ALL, except that the index tree is scanned. This occurs two ways:
触发条件:
只扫描索引树
1)查询的字段是索引的一部分 , 覆盖索引 。2)使用主键进行排序
 文章插图
文章插图
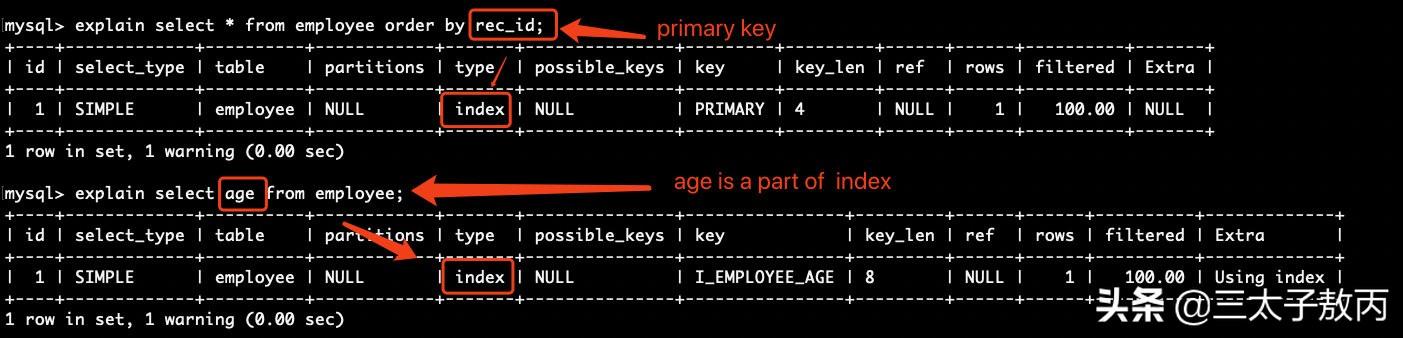
all触发条件:全表扫描 , 不走索引
优化数据访问减少请求的数据量
- 只返回必要的列:最好不要使用 SELECT * 语句 。
- 只返回必要的行:使用 LIMIT 语句来限制返回的数据 。
- 缓存重复查询的数据:使用缓存可以避免在数据库中进行查询 , 特别在要查询的数据经常被重复查询时 , 缓存带来的查询性能提升将会是非常明显的 。
重构查询方式切分大查询一个大查询如果一次性执行的话 , 可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询 。
DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH);rows_affected = 0do {rows_affected = do_query("DELETE FROM messages WHERE create< DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000")} while rows_affected > 0分解大连接查询将一个大连接查询分解成对每一个表进行一次单表查询 , 然后在应用程序中进行关联 , 这样做的好处有:- 让缓存更高效 。 对于连接查询 , 如果其中一个表发生变化 , 那么整个查询缓存就无法使用 。 而分解后的多个查询 , 即使其中一个表发生变化 , 对其它表的查询缓存依然可以使用 。
- 分解成多个单表查询 , 这些单表查询的缓存结果更可能被其它查询使用到 , 从而减少冗余记录的查询 。
- 减少锁竞争;
- 在应用层进行连接 , 可以更容易对数据库进行拆分 , 从而更容易做到高性能和可伸缩 。
- 查询本身效率也可能会有所提升 。 例如下面的例子中 , 使用 IN() 代替连接查询 , 可以让 MySQL 按照 ID 顺序进行查询 , 这可能比随机的连接要更高效 。
SELECT * FROM tagJOIN tag_post ON tag_post.tag_id=tag.idJOIN post ON tag_post.post_id=post.idWHERE tag.tag='mysql';SELECT * FROM tag WHERE tag='mysql';SELECT * FROM tag_post WHERE tag_id=1234;SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);事务事务是指满足 ACID 特性的一组操作 , 可以通过 Commit 提交一个事务 , 也可以使用 Rollback 进行回滚 。ACID事务最基本的莫过于 ACID 四个特性了 , 这四个特性分别是:
- Atomicity:原子性
- Consistency:一致性
- Isolation:隔离性
- Durability:持久性
事务被视为不可分割的最小单元 , 事务的所有操作要么全部成功 , 要么全部失败回滚 。
一致性
数据库在事务执行前后都保持一致性状态 , 在一致性状态下 , 所有事务对一个数据的读取结果都是相同的 。
隔离性
一个事务所做的修改在最终提交以前 , 对其他事务是不可见的 。
持久性
一旦事务提交 , 则其所做的修改将会永远保存到数据库中 。 即使系统发生崩溃 , 事务执行的结果也不能丢 。
ACID 之间的关系事务的 ACID 特性概念很简单 , 但不好理解 , 主要是因为这几个特性不是一种平级关系:
- 只有满足一致性 , 事务的结果才是正确的 。
- 在无并发的情况下 , 事务串行执行 , 隔离性一定能够满足 。 此时只要能满足原子性 , 就一定能满足一致性 。 在并发的情况下 , 多个事务并行执行 , 事务不仅要满足原子性 , 还需要满足隔离性 , 才能满足一致性 。
- 腾讯申请「打工鹅」商标,网友:“虾仁猪心”
- 库克靠打工实现1个亿“小目标”iPhone 12全球热销功不可没
- 支付宝打造的天价蚂蚁森林,四年时间过去了,现在长成什么样了?
- 没有人在意你的网易云年终总结
- 商标|腾讯申请打工鹅商标
- 资深打工人回血神器,荣泰RT6908S按摩椅评测
- 腾讯企鹅跟上“打工人”热潮!背后暗藏港股之王的成功秘诀
- 腾讯申请“打工鹅”商标
- 腾讯云交出阶段性年终总结,发布5G产品矩阵
- 小白财经|一图看懂5G毫米波