了解情绪划分:如何使用机器学习来保持积极心态?
全文共2208字 , 预计学习时长6分钟
 文章插图
文章插图
“思考再思考 , 然后采取行动” , 这样的流程是不是听起来很熟悉?大多数人都是这样做的 。
然而 , 这个思考流程很可能是一把双刃剑:在一些情形下 , 结果可能积极有用 , 但在另一些情形下 , 结果可能有害 , 甚至反噬自身 。 后者是我们都希望避免的 。 为了清晰了解情绪的划分 , 我编写了这个机器学习(ML)程序 。
隔离阶段让我有机会探索自我并审视自己的思路 。 我不是一个沉思者 , 但是总会陷入纷乱的思绪之中 , 每当这时 , 我都需要理清思路 。 因此我要创建一个可以分析我的思考过程的ML模型 。 我用KNN算法判断应该避免的情绪 , 并通过可视化技术将我的情绪以图形展示 , 使我清晰地一览全貌 。 下面是我的做法:
· 作为开始 , 我创建了一个有不同想法的数据集;
· 使用KNN算法;
· 使用可视化技术;
· 最后 , 我学会了分割思考过程 。
 文章插图
文章插图
创建数据集数据集由九种情绪(特征)组成:沮丧 , 悲伤 , 卑微 , 哭泣 , 痛苦 , 困惑 , 快乐 , 振奋和坚定 。 我将它们分为三类(标签):积极 , 消极和中立 。 另外 , 我根据标签对这九种情绪/特征均按1-10的标准进行了评分 。 于是我创建了共150个案例 。 这是数据集的前几行:
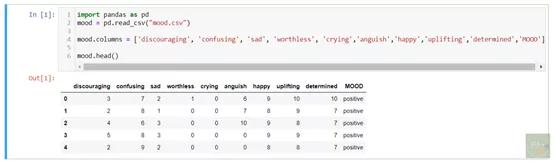 文章插图
文章插图
文章插图
使用KNN算法在开始下一步之前 , 首先需要掌握一些监督式学习的ML基本术语:
· 为了训练、测试和评估一个模型 , 我们使用一系列案例;
· 这些案例包括与模型相关的特征和标签值;
· 特征是用于训练算法的基础值;
· 一旦训练部分结束 , 算法就能预测测试特征的正确标签值 。
目标是正确预测标签 。 因此 , 受训算法的精度应该很高 。 如果不高 , 应使预测的标签值和原本标签之间的误差最小化 。 有了这些基础知识 , 让我们接着来了解KNN算法 。 KNN是监督式的机器学习算法 , “K”是待分类点邻近值的个数 (例如 , K=1、2、3等) 。
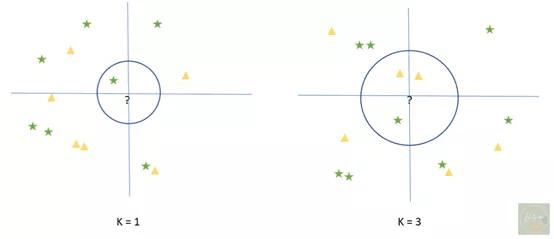 文章插图
文章插图
左图中 , KNN会将“?”归类为绿色星星 , 因为它最近 。 同样 , 在右例中KNN会将“?”归为黄色三角 , 因为这些三角形是最接近的多数情况 。
新案例与已知案例之间的接近程度 , 可以使用任意距离函数 , 如欧几里得尺度和明可夫斯基尺度等体现 。 因此称之为最邻近 。 这样 , KNN算法对新案例进行了分类 。 在这种特定模式中 , KNN要正确预测各个情绪的分类 。 预处理所有数据后 , 我使用了KNN算法 , 然后计算出准确度为98.6% 。 这是显示相同的代码段:
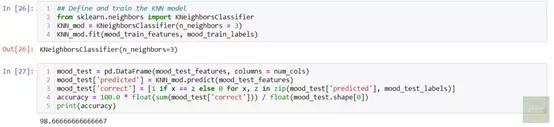 文章插图
文章插图
文章插图
使用可视化技术我用数据可视化进行了分类 , 图表更便于理解 , 并创建了一种解决方案 , 用来预测我应该避免什么样的情绪才能保持一个积极的心态 。 这个技术将帮助我分辨标签类别(积极、消极和中性) , 为此我使用了“箱形图” 。
文章插图
结果
- iQOO 7邀请函曝光“马”“鸭”“羊”代表什么
- 更便宜的米11系列新品要来了,小米11Lite了解下
- 人工智能正在了解人类的“言外之意”
- 华为要让专家当家,你了解华为吗?华为对于中国创业者真正的意义
- 曲面电竞显示器了解一下 环绕视觉沉浸体验
- 三星新机专利曝光,伸缩式屏下镜头了解下
- 擦地机器人品牌排行榜来了,你想了解的都在这里
- 诺基亚5G订单数已破百,爱立信更是达到118个,那华为呢?
- 谷歌AI又获重大突破!新算法无需了解规则也能自学成“棋”
- 买下一部手机手机前 请了解一下OriginOS