内容推荐算法:异构行为序列建模探索( 二 )
? 序列建模的必要性推荐系统的首要任务是精准的捕捉用户意图 , 早期的人工抽取content-based feature(如商品的叶子类目)作trigger的方式过于粗浅 , 有兴趣粒度不足及trigger间无法有效排序两处弊端 , 分别讨论 。
1、content feature粒度不够精细 , 譬如 {方便粉丝 , 米线 , 螺蛳粉} 三个品类共用一个叶子类目;又如连衣裙直接作为叶子类目 , {A字裙 , 荷叶边裙 , 百褶裙} 等款式差异无从体现 , 而不同的女孩子多半有着差异化的兴趣指向 。
2、feature庞杂难以取舍 。 洋淘用户多从首猜轻应用跳转而来 , 他们的商品点击行为丰富且多样 , 并且 , 把时间窗口扩大到七天 , 一个月 , 这些叶子类目兴趣trigger会更加膨胀 , 能召回成百上千个符合要求的洋淘内容 , 但推荐系统一次只返回一页有限个内容 , 如此多的兴趣作何取舍呢?典型的做法是 ,综合考虑这些叶子类目对应商品的 {交互行为 , 交互次数 , 时间新旧} ,给不同的叶子类目计算权重然后倒排 , 但这么计算兴趣分布也很粗糙 , 指标归因中可以看到叶子类目兴趣召回的效果是低于大盘指标的 。
所以我们不能孤立地看待这一次次点击行为 , 分别抽取各自的 content-based feature 作trigger 。 完整的交互序列直接体现了用户过往来到淘宝逛了啥点了啥 , 且包含了时间的演进 , 直观上以及业界论文经验都能证明 , 日志中的交互序列对接下来的点击预测具有十分重要的指导意义 , 且价值远胜于{年龄 , 性别 , 地域}等用户画像信息 。
? 注意力机制Attention Mechanism 是近来大放异彩 , 业界青睐的建模手段 。 它允许模型在做当下的决策时 , 只把注意力放在最应该关注的那一部分 , 不再眉毛胡子一把抓 。
scaled dot-product attention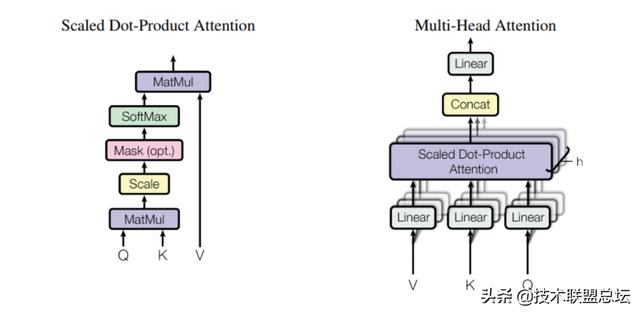 文章插图
文章插图
图1-4.multi-head attention 图示
Dot-product attention 相较于传统的 RNN/CNN layer 的类attention处理 , 无论是训练效率上还是 long-range dependency 情形下的表现均有显著优势 。 它可以描述为这么一个映射 , output=f(query , {key_value}), 它们全都是向量 。 先计算query与若干个key的紧密程度得到affinity matrix , 再归一化后把这些weight分配到相应的value上 , 最终求和 , 就得到了一个query在attention后的最终表达 。
self attention自注意力 , 即在encoder与decoder两侧 ,各自对同一sequence内的各个item间的关联做计算 。 它有啥好处呢 , 以图1-5为例 , 孤立看用户的某一次点击 , 我们很难知道背后的意图 , 就像人类在做阅读理解时碰到多义词 , 需要联系上下文才能判断具体的含义 。 这里也一样 , 通过 self attention 可得到一个交互商品(或内容)的上下文表达 , 即 contextual representation 。
 文章插图
文章插图
图1-5.孤立看用户的某一次点击 ,我们很难知道背后的意图
vanilla attention它指的是decoder对encoder , 一个序列对另一个序列的attention 。 这个更直观一点 , 相当于把下面的问题抛给了模型 , 让它自己去学自己去学——即用户当下的一次点击 , 应归因到又长又丰富的前序点击序列中的哪几次点击所体现出来的用户兴趣上呢?
? 多模态特征我们的推荐数据集是非常稀疏的 。 为此分别通过 BERT in NLP及 ResNet in CV 这些流行预训练模型做二次开发 , 产出期望的多模态特征 , 提升泛化性 。 消融实验表明此项子工作带来了额外+5%的性能提升 。
 文章插图
文章插图
图1-6.BERT additional pre-train 指标:masked_lm_accuracy=73.52% ,nsp_accuracy=99.33% , 框选商品作query , 基于此作标题k近邻验证
- 微软调侃WhatsApp隐私策略调整 并推荐用户迁移至Skype
- 玩转光追大作最低需要什么配置?快来看小狮子的推荐
- 身边噪音烟消云散 三款颈挂式降噪蓝牙耳机推荐
- 爽玩光追大作,RTX 3060Ti性价比电脑推荐
- 多多|拼多多:知乎账号内容系供应商员工自行发布,不代表公司态度
- “记”兴之作 智能手写本推荐——柔宇RoWrite 2
- 小米11再开售,小米有品推荐这3款手机配件
- 小米 11 官方保护壳被吐槽 后摄无保护根本不值得推荐
- 在谷歌算法更新之后2020年盗版网站流量锐减三分之一
- 内容|喜马拉雅与小米达成战略合作,打造AIOT场景新体验