数据不平衡问题( 四 )
评价指标 – MacroP, MicroP等
Macro Precision= 1/n ∑_(i=1)^n?P_i
Macro Recall= 1/n ∑_(i=1)^n?R_i
Macro F_1= (2×MacroP×MacroR)/(MacroP+MacroR)
Micro Precision=(TP) ?/((TP) ?+(FP) ? )
Micro Recall=(TP) ?/((TP) ?+(FN) ? )
Macro F_1= (2×MacroP×MacroR)/(MacroP+MacroR)
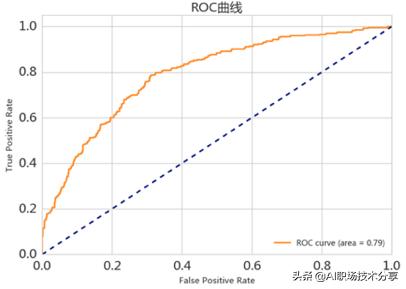
评价指标 – ROC与AUC
?TPR(True Positive rate) : TP / (TP + FN)
?FPR(False Positive rate): FP / (FP + TN)
ROC_AUC表示ROC曲线下方的面积 , 横轴FPR , 纵轴TPR ,这是在实际建模中经常使用的衡量分类模型的效果的指标
?优点:兼顾正例和负例的权衡
 文章插图
文章插图
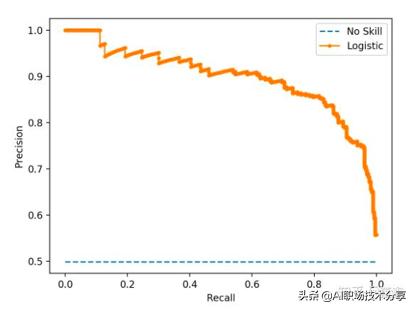
评价指标 – PR-AUC曲线
?纵坐标查准率 , 即精确率(Precision)
?横坐标查全率 , 即召回率(Recall)
 文章插图
文章插图
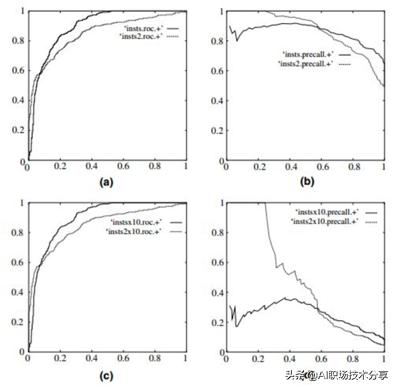
ROC-Curve和PR-Curve的区别
 文章插图
文章插图
?负例增加了10倍 , ROC曲线没有改变 , 而PR曲线则变了很多 。 作者认为这是ROC曲线的优点 , 即具有鲁棒性 , 在类别分布发生明显改变的情况下依然能客观地识别出较好的分类器 。
?在类别不平衡的背景下 , 负例的数目众多致使FPR的增长不明显 , 导致ROC曲线呈现一个过分乐观的效果估计 。
ROC-Curve和PR-Curve的应用场景
?ROC曲线由于兼顾正例与负例 , 所以适用于评估分类器的整体性能 , 相比而言PR曲线完全聚焦于正例 。
?如果有多份数据且存在不同的类别分布 , 比如信用卡欺诈问题中每个月正例和负例的比例可能都不相同 , 这时候如果只想单纯地比较分类器的性能且剔除类别分布改变的影响 , 则ROC曲线比较适合 , 因为类别分布改变可能使得PR曲线发生变化时好时坏 , 这种时候难以进行模型比较;反之 , 如果想测试不同类别分布下对分类器的性能的影响 , 则PR曲线比较适合 。
?如果想要评估在相同的类别分布下正例的预测情况 , 则宜选PR曲线 。
?类别不平衡问题中 , ROC曲线通常会给出一个乐观的效果估计 , 所以大部分时候还是PR曲线更好 。
?最后可以根据具体的应用 , 在曲线上找到最优的点 , 得到相对应的precision , recall , f1 score等指标 , 去调整模型的阈值 , 从而得到一个符合具体应用的模型 。
自然语言处理中的数据增强
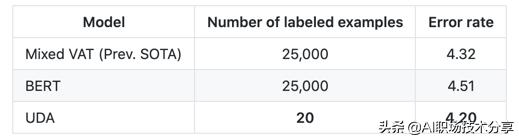
?UDA
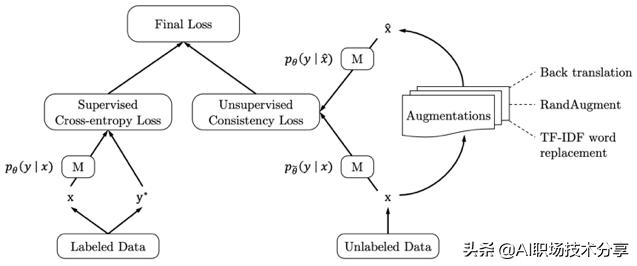
?Unsupervised Data Augmentation , 一个半监督的学习方法 , 减少对标注数据的需求 , 增加对未标注数据的利用
?在IMDB数据集上 , UDA仅仅使用20个标注的数据就可以达到SOTA的效果 。
 文章插图
文章插图
 文章插图
文章插图
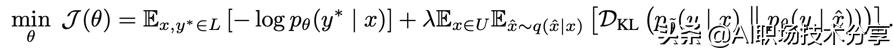 文章插图
文章插图
?UDA使用的语言增强技术
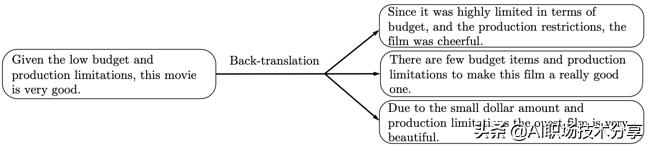
?Back-translation:回译能够在保存语义不变的情况下 , 生成多样的句式 。 实验证明 , 在QANet上 , 这种策略取得了良好的效果 。 因此作者在情感分类问题等数据集 , 如IMDb, Yelp-2, Yelp-5, Amazon-2 、Amazon-5上采用了这种策略 , 同时 , 他们发现 , 句式的多样性比有效性更重要 。
 文章插图
文章插图
?EDA
?easy data augmentation
- 一则消息传来,苹果iPhone12再现问题,“果粉”有点慌
- 与荷兰光刻机完成联机!国产芯片设备传来喜讯:技术问题已经解决
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 国产芯再传好消息,关键技术问题已经解决,与荷兰光刻机联机成功
- 黑客窃取250万个人数据 意大利运营商提醒用户尽快更换SIM卡
- 小米11屏幕翻车发绿怎么回事 屏幕问题检测方法介绍
- 装机点不亮 如何简易排查硬件问题?
- 消费者报告 | 美团充电宝电量不足也扣费,是质量问题还是系统缺陷?
- 谷歌修复Pixel 5系统音量问题 快门音效不再吵
- 谷歌发布一月安全补丁 修复Pixel音频、应用重启等问题