别再用假任务做小样本学习实验了!快来试试全新小样本基准数据集FewJoint( 二 )
1.3 数据集统计
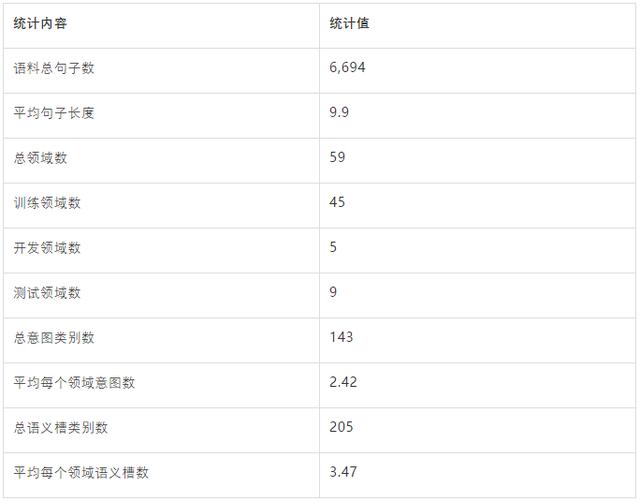
表1是我们收集的原始用户语料信息以及相应的语义框架标注信息 。
 文章插图
文章插图
表1:FewJoint 原始数据统计
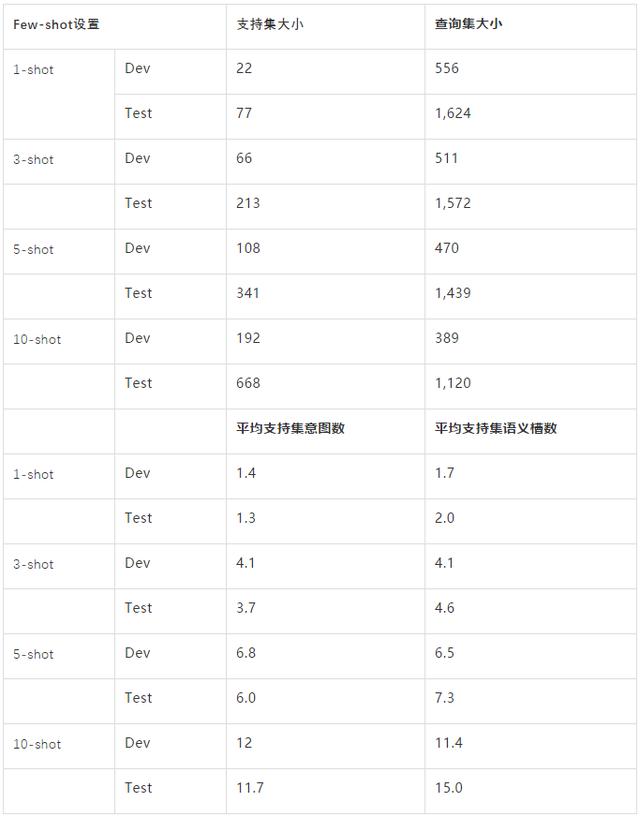
表2是我们重构后的小样本评测集信息 , 我们提供4种shot 设置:1 , 3 , 5 , 10 。 其中 , 3-shot是我们所推荐的主设置 。
 文章插图
文章插图
表2:小样本数据统计信息
1.4 实验结果
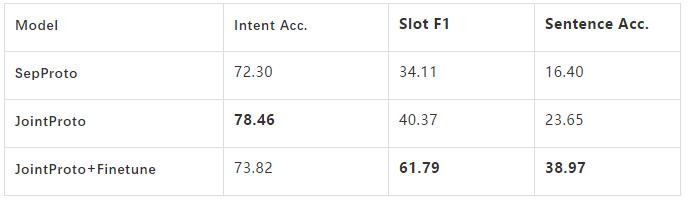
这里我们给出基于该数据集的baseline结果 , 在Prototypical Network (SepProto)[1] 基础上 , 我们尝试了两种常用的trick:
(1) Joint:联合学习Intent和Slot 。
(2) Finetune: 在目标domain精调Metric函数 。
实验结果如表3所示 , 可以看到JointProto明显地优于SepProto , 这体现出了联合学习Intent和slot的必要性 。 同时Finetune的结果提升也显示出了通过精调来适应目标领域的重要性 。
 文章插图
文章插图
表3:主要Baseline实验结果
2 SMP2020-ECDT小样本对话理解评测介绍
2.1比赛概况
ECDT中文人机对话技术评测(The Evaluation of Chinese Human-Computer Dialogue Technology)是SMP全国社会媒体处理大会的评测项目之一 , 我们在今年的评测中首次引入了小样本对话语言理解技术任务 。
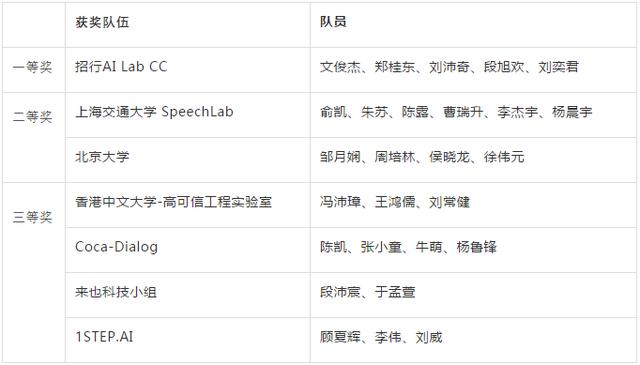
经过近4个月的激烈角逐 , 来自招行AI Lab、上海交通大学、北京大学、香港中文大学等队伍获得了奖项 。 完整的获奖名单如下:
 文章插图
文章插图
表4:评测获奖名单
2.2 参赛方法
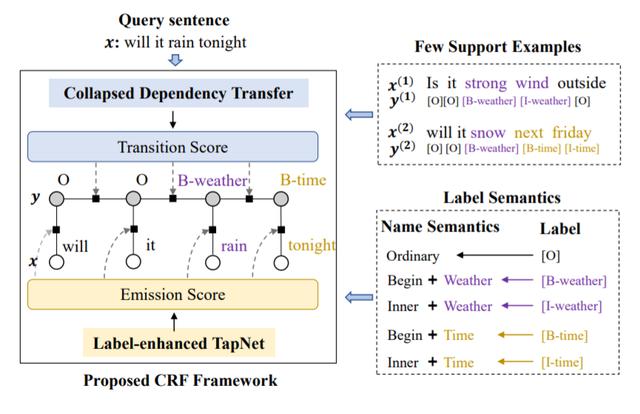
在采用的比赛方法方面 , 参赛队基本都使用了Finetuning和Joint Learning的技巧 , 前几名的方法都使用了基于Metric Learning的小样本学习框架 , 并采用了Collapse Dependency Transfer [2] 策略处理小样本下的序列标注问题 。 第一名的解决方案的模型主体构建于本基准数据集提供的平台MetaDialog , 在语义槽识别中还引入了L-TapNet模型 [2] 。 在解决意图识别上 , 参赛队主要Finetune简单的分类器 , 或者利用原型网络Prototypical Network 。 其中 , 前者展示出更好的效果 。
Collapsed Dependency Transfer和L-TapNet是ACL 2020 长文Few-shot Slot Tagging [1] 中提出的方法 。 具体的 , 为了建模标签之间的依赖关系(Transition Score) , 该工作提出了一种跨领域建模标签依赖关系的方法——坍缩依赖迁移(Collapsed Dependency Transfer ,CDT) 。 CDT首先从数据充足的源域(Source Domain)学习抽象标签依赖关系 , 并在小样本的目标域中泛化学到的依赖关系来辅助标签序列的预测 。
为了在小样本情形下得到每个词的标签概率(Emission Score) , 该工作还提出了L-TapNet , 来基于每个词和不同标签表示的相似度计算属于不同标签的概率 。 L-TapNet在计算时利用了label名字中的语义信息 , 并通过线性偏差消除法(Linear-error ing)构造映射空间来将不同标签类别在embedding空间有效分开 。
 文章插图
文章插图
图3:在比赛中大量使用的基于CDT的CRF架构
3 小样本平台工具MetaDialog
我们为FewJoint数据集提供了一个完全适配的自然语言小样本工具平台——MetaDialog 。 它为两种主要的自然语言任务(文本分类和序列标注)提供Few-shot Learning下的解决方案 。 该平台的主要特点如下:
(1)SOTA 解决方案
? 支持CDT[2] 用于序列标记任务的Few-shot Learning 。
- 运营商超额完成任务,明年再建百万5G基站,手机终于有信号了?
- 比中高端市场大10倍的下沉市场,「飞任务」想做他们的协同平台
- 曝微软自研ARM芯片:不再用intel处理器
- 经常用华为手机,记得打开开发者选项,一键流畅再用3年
- 库克加快自研步伐,iPhone13不再用高通基带,信号稳了!
- 使用Kafka和Kafka Stream设计高可用任务调度
- 深海|华为IdeaHub与“奋斗者”同行,协同完成海底科考任务
- 安卓还敢做小屏旗舰?iPhone 12 mini预约量最少
- 别再用扫描仪了,手机就能一键扫描文档!30秒电子化很简单
- 电脑任务栏隐藏图标图文教程,系统任务栏右下角程序图标显示方法