京东数科JUST技术:利用迁移学习生成新城市的轨迹( 二 )
其实换一种问法就是 , 产生的出行意图 , 最接近目标城市从哪里到哪里的意图?这就转成了是一个相似查询问题 。
 文章插图
文章插图
图 5
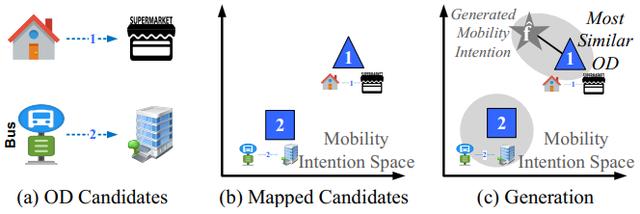
图5形象化了该模块的执行过程 。 分为三步:
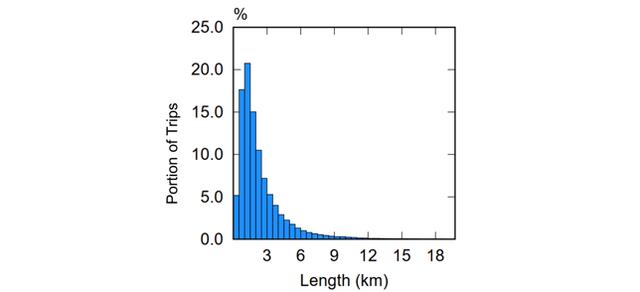
首先是候选起终点获取 。 我们先计算目标城市的所有可能出现的起终点对 。 根据相关研究 , 91.7%的短途出行集中在6公里以内 。 因此 , 该工作枚举了目标城市所有6公里以内的起终点作为候选集 。
 文章插图
文章插图
然后 , 通过同样的空间信息特征提取方法 , 和上一模块学得的域泛化函数G , 得到目标城市的起终点候选集映射的出行意图信息(图5b) 。
最后 , 如图5c , 利用上一模块生成出行意图f , 并查找与其最相似的目标城市的候选起终点作为最终的生成结果 。 该工作对出行意图空间中的目标城市的候选OD集建立KD-Tree索引 , 提高了相似性查询的效率 。
4. 路线生成在解决了起终点生成之后 , 另一个问题是 , 如何生成起终点间的具体路径?人们对路线的偏好 , 取决于路线本身的特征:是否是大路、需要经过多少个拐弯、路程是否接近最近路程长度等等 。 基于此思想 , 该工作的路线生成分为两步:
 文章插图
文章插图
图 6
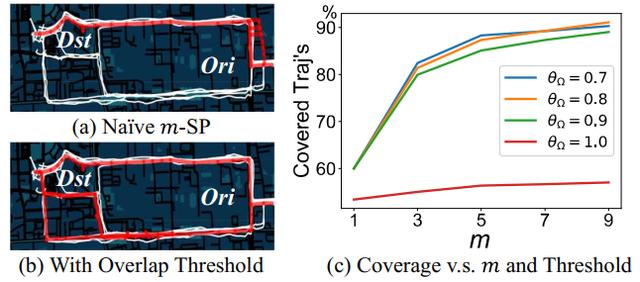
首先是候选路线集生成 。 作者发现 , 大部分轨迹都会选择最短或者接近最短的路线来完成出行 。 为此 , 该工作对起终点计算了前m短非重叠路线 , 作为候选路线集 。 这里注意该工作并非直接使用前m短路线作为候选路线 , 这是因为 , 前m短路线往往近乎重叠在一起(图6a) 。 该工作通过wJCD指标计算两条路径的重叠指数 , 设定wJCD值θ作为重叠阈值 , 筛掉重叠度高的路径 。
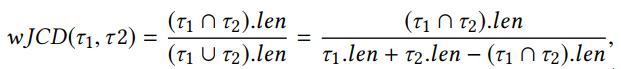 文章插图
文章插图
那前m短非重叠路线是否覆盖了大部分轨迹呢?图6c统计了真实数据中 , 轨迹的覆盖比例与m、非重叠阈值θ的关系 。 可以看出 , 当选择非重叠阈值为0.7的前5短路径时 , 已经可以覆盖将近90%的真实轨迹 , 而不引入非重叠条件(θ=1)时只能覆盖少量轨迹 。 这证实了非重叠约束的有效性 。
 文章插图
文章插图
图 7
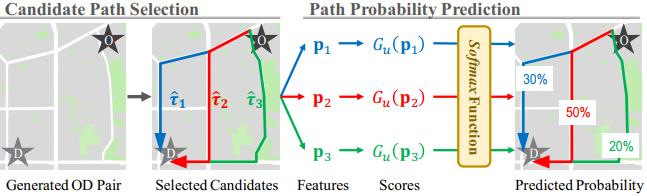
其次是选择各条候选路线集的概率计算 。 该工作通过类似于排序问题中的Listwise方式进行训练 , 得到各条路线的概率 。 如图7所示 , 对给定的起终点OD , 先获取三条候选路线 , 并进行路线特征提取分别得到p1 , p2 , p3 。 评分函数Gu会给各条路线进行打分 , 并通过Softmax函数转为最终的概率分布 , 再以真实轨迹数据的分布算得交叉熵损失 , 来训练Gu评分函数 。 该工作中 , Gu采用多层全连接网络实现 。
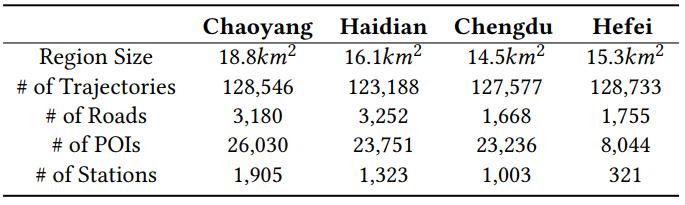
5. 实验作者通过四个城市区域来验证该方法的有效性:北京朝阳区、北京海淀区、成都、合肥 , 覆盖了一、二、三线城市 。 数据包含了:轨迹数据、POI数据、路网数据、交通站点数据 。 下表列出了详细的统计量信息 。
 文章插图
文章插图
该工作的任务是在目标城市比较生成的轨迹与真实轨迹的分布是否一致 。 对轨迹分布 , 如何设置评判标准呢?作者认为 , 现有的工作会直接比较轨迹热力图的分布一致性并不严谨 , 因为不同的轨迹集合可以产生同样的轨迹热力分布 。 为此 , 作者采用两步验证来衡量结果的准确性 , 即起终点分布和路线偏好分布——这是因为如果起终点分布准确 , 且基于起终点的路线偏好分布准确 , 则最后的轨迹分布也准确 。 起终点可以看作一对经纬度
- 美妆购物可以“1小时达”了,京东携达达、悦诗风吟打造即时零售新模式
- 打造数智化协同生态 京东超市携手五常共建复合型产业带集群
- 看看日本企业的食堂,再看看中国京东的食堂,网友:差距也太大了
- 京东收购美菜网旗下美家买菜
- 京东双十一手机销量榜:iPhone12未进前十,第一无人能敌
- 京东电脑数码11.11新趋势 智能穿戴同比增150%
- 京东员工吐槽:领导总让员工加班,还不加工资,已经没有心情工作
- 京东物流上市在即!问题来了,京东顺丰谁是中国“物流一哥”?
- 京东|京东探索稀疏三维空间点云Global Context学习方法获认可
- 除了贵,你可能对京东一无所知