由多线程内存溢出产生的实战分析( 三 )
在系统异常的时候 , 监控系统能够自动调用脚本产生信息文件 , 有了这些文件分析问题才能够得心应手 , 不然出了问题根本无从查起 , 只能是没头苍蝇乱撞 。
压测分析在压测环境中配置与生产环境一样的硬件环境和配置环境进行压测 , 可以看到如下的测试图:
 文章插图
文章插图
通过压测分析 , 在程序并发线程达到1010个的时候 , 就报出unable to create new native thread异常 , 查看上面这张图其实不难看出 , 应用程序中并没有使用线程 , 但是在Log4j中却大量的使用了synchronized这个关键字 , 在并发非常高的时候会产生非常多的阻塞 , 最终内存资源耗尽报出内存溢出错误 。
问题解决方案问题解决方案1、优化程序 , 减少没用的log4j日志输出 , 将log4j日志改为异步+buffer的模式 。 2、单台服务器本身性能有限 , 通过增加服务器的方式提高扩展性 。 3、将系统的一些限制属性增大 , 如:ulimit -a 。
通用解决方案上面的四点是针对我们的解决方案 , 但通过以上的这些分析 , 我们不难发现所有的unable to create new native thread的错误异常都有其共性的地方 , 那接下来我再总结一些相对通用一点的方法帮助大家在以后遇到类似的问题的时候 , 能够有据可查知道如何进行逐步的排查 。
1、当发现这个错误的时候 , 第一时间要排查程序是否有bug , 是否大量的创建了线程 , 或者没有正确使用线程池 , 比如:是否使用了Executors.newCachedThreadPool()方法 , 该方法能创建Integer最大值个线程 , 创建到一定程度的时候系统资源耗尽就会报错 。
2、如果发现程序中并没有使用线程却依然报这个错 , 那么观察一下这个时刻的并发情况如何 , 要是溢出的这一时刻比其他时候并发量都要大 , 这时先查看一下系统资源的情况 , 使用ulimit –a查看max user processes和open files这二个属性的值越大 , 能创建的线程数也就越大 。 3、如果以上二个属性调大依然报错的话 , 说明此时受限于系统内存资源了 , 要是服务器本身内存就比较小的话 , 建议增加内存 。 要是服务器内存比较大 , 就需要通过调整jvm参数来增加线程使用的内存 , 比如减小-Xss值 , 这个值越小能创建的线程数也就越多 , 也可以适当减少-Xmx和-Xms的值 , 增加堆外内存的容量 。
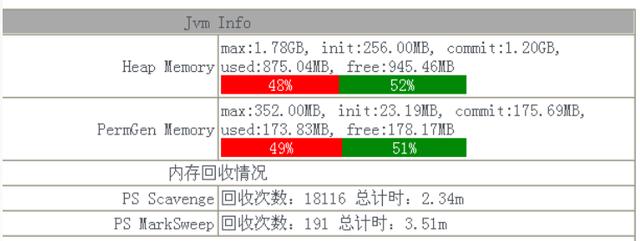
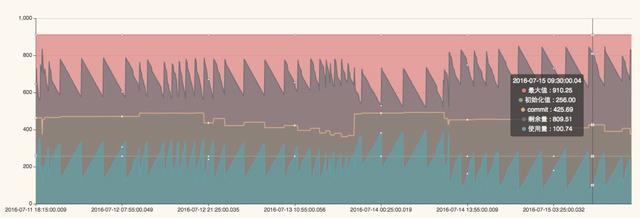
回顾总结在我们排查整个内存溢出问题的过程中 , 其实耗费了挺长时间 , 而且报错的时间基本都是在晚上 , 分析交易量看到这个时间段的并发量确实比白天要高 , 给我们最大的启示是发生问题的时候 , 不能很快的定位问题原因 , 没有最重要的报错日志可供分析 。 基于此我们开发了JAVA探针功能 , 可以实时采集当前服务器的内存使用情况、JVM堆使用情况 , 栈使用情况等等 , 并且能够提前预警 , 界面类似下面这样:
 文章插图
文章插图
 文章插图
文章插图
注:第一张图显示的内存使用的百分比 , 第二张图可以查看一段时间jvm内存使用情况 , 当高峰期来临时可以提前预警 。
转载于:
作者:兔兔七
- Python高级技巧:用一行代码减少一半内存占用
- 一文讲透“进程、线程、协程”
- Nokia 5.4规格曝光:6.39吋屏幕+骁龙662+4GB内存+4000mAh电池
- 电脑之间不能一概而论?AMD线程撕裂者3990X整机上手体验
- 国产内存价格首降,你愿意多花19为它披上国风战甲吗?
- 《深入理解Java虚拟机》:锁优化
- 摩托罗拉Moto G Play(2021)跑分曝光:3GB内存+Android 10
- JVM 之java内存模型
- Redis的线程模型和事务
- 完全不够用!为什么苹果还在出64GB内存的产品?