火了50年的技术—布隆过滤器( 二 )
二、删除困难到这里我不说大家应该也明白为什么吧 , 作为你们的暖男老哥 , 还是讲一下吧 。
还是用上面的举例 , 因为“你好”和“hello”的hash值相同 , 对应的数组下标也是一样的 。
这时候老哥想去删除“你好” , 将下标为2里的二进制数据 , 由1改成了0 。
那么我们是不是连“hello”都一起删了呀 。 (0代表有这个数据 , 1代表没有这个数据)
到这里是不是对布隆过滤器已经明白了 , 都说了我是暖男 。
 文章插图
文章插图
实现布隆过滤器有很多种实现方式 , 其中一种就是Guava提供的实现方式 。
一、引入Guava pom配置...if (someobject != null) {someobject.doCalc();}...复制代码二、代码实现【火了50年的技术—布隆过滤器】这里我们顺便测一下它的误判率 。
import com.google.common.hash.BloomFilter;import com.google.common.hash.Funnels;public class BloomFilterCase {/*** 预计要插入多少数据*/private static int size = 1000000;/*** 期望的误判率*/private static double fpp = 0.01;/*** 布隆过滤器*/private static BloomFilter运行结果:
 文章插图
文章插图
10万数据里有947个误判 , 约等于0.01% , 也就是我们代码里设置的误判率:fpp = 0.01 。
深入分析代码核心BloomFilter.create方法
@VisibleForTestingstaticBloomFilter create(Funnel funnel, long expectedInsertions, double fpp, Strategy strategy) {。。。。 }复制代码这里有四个参数:
- funnel:数据类型(一般是调用Funnels工具类中的)
- expectedInsertions:期望插入的值的个数
- fpp:误判率(默认值为0.03)
- strategy:哈希算法
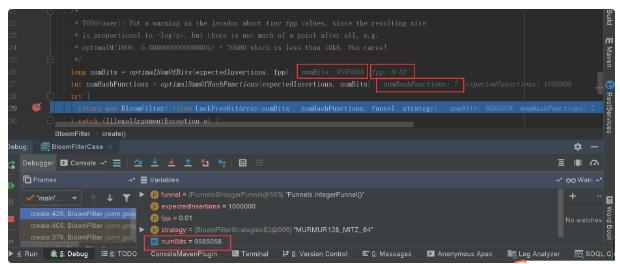
fpp误判率情景一:fpp = 0.01
- 误判个数:947
 文章插图
文章插图- 占内存大小:9585058位数
 文章插图
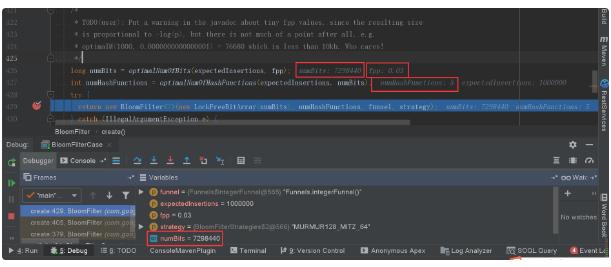
文章插图情景二:fpp = 0.03(默认参数)
- 误判个数:3033
 文章插图
文章插图- 占内存大小:7298440位数
 文章插图
文章插图情景总结
- 误判率可以通过fpp参数进行调节
- fpp越小 , 需要的内存空间就越大:0.01需要900多万位数 , 0.03需要700多万位数 。
- fpp越小 , 集合添加数据时 , 就需要更多的hash函数运算更多的hash值 , 去存储到对应的数组下标里 。 (忘了去看上面的布隆过滤存入数据的过程)
- 「技术」这样的思路,让控制器中按键处理数据的方法变得简单了
- Chiplet如何开拓半导体技术的未来
- 物联网相关的技术、商业生态
- 学大数据是否有前途 如何系统掌握大数据技术
- Linux培训完能到什么水平,之后还需要学习哪些技术?
- 微纳机电系统与微纳传感器技术 发展报告摘要
- 指纹|指尖上的密码——指纹识别
- 满屏的try-catch,不瘆得慌?
- 技术 | 室内LED屏亮度并非越高越好?“低亮高灰”很关键
- 5G后还会有6G、7G、8G吗?美国跳过5G发展6G是否现实