详解工程师不可不会的LRU缓存淘汰算法( 二 )
我们把上面的内容整理一下 , 可以得到几点要求:
- 保证缓存的读写效率 , 比如读写的复杂度都是O(1)
- 当一条缓存当中的数据被读取 , 将它最近使用的时间更新
- 当插入一条新数据的时候 , 弹出更新时间最远的数据
如果是在面试当中被问到想到这里的时候 , 可能很多人都已经束手无策了 。 但是先别着急 , 我们冷静下来想想会发现问题其实并没有那么模糊 。 首先HashMap是一定要用的 , 因为只有HashMap才可以做到O(1)时间内的读写 , 其他的数据结构几乎都不可行 。 但是只有HashMap解决不了更新以及淘汰的问题 , 必须要配合其他数据结构进行 。 这个数据结构需要能够做到快速地插入和删除 , 其实我这么一说已经很明显了 , 只有一个数据结构可以做到 , 就是链表 。
链表有一个问题是我们想要查询链表当中的某一个节点需要O(n)的时间 , 这也是我们无法接受的 。 但这个问题并非无法解决 , 实际上解决也很简单 , 我们只需要把链表当中的节点作为HashMap中的value进行储存即可 , 最后得到的系统架构如下:
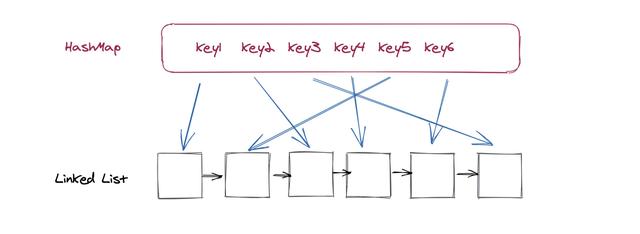 文章插图
文章插图对于缓存来说其实只有两种功能 , 第一种功能就是查找 , 第二种是更新 。
查找查找会分为两种情况 , 第一种是没查到 , 这种没什么好说的 , 直接返回空即可 。 如果能查到节点 , 在我们返回结果的同时 , 我们需要将查到的节点在链表当中移动位置 。 我们假设越靠近链表头部表示数据越旧 , 越靠近链表尾部数据越新 , 那么当我们查找结束之后 , 我们需要把节点移动到链表的尾部 。
移动可以通过两个步骤来完成 , 第一个步骤是在链表上删除该节点 , 第二个步骤是插入到尾部:
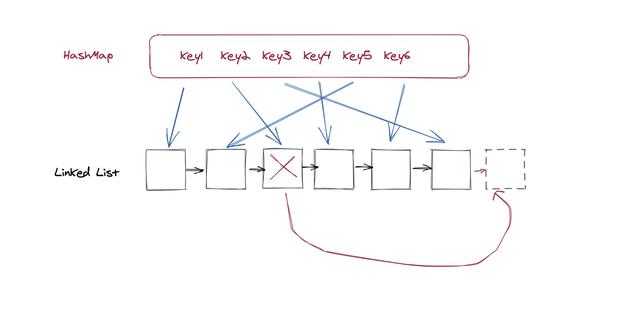 文章插图
文章插图更新更新也同样分为两种情况 , 第一种情况就是更新的key已经在HashMap当中了 , 那么我们只需要更新它对应的Value , 并且将它移动到链表尾部 。 对应的操作和上面的查找是一样的 , 只不过多了一个更新HashMap的步骤 , 这没什么好说的 , 大家应该都能想明白 。
第二种情况就是要更新的值在链表当中不存在 , 这也会有两种情况 , 第一个情况是缓存当中的数量还没有达到限制 , 那么我们直接添加在链表结尾即可 。 第二种情况是链表现在已经满了 , 我们需要移除掉一个元素才可以放入新的数据 。 这个时候我们需要删除链表的第一个元素 , 不仅仅是链表当中删除就可以了 , 还需要在HashMap当中也删除对应的值 , 否则还是会占据一份内存 。
因为我们要进行链表到HashMap的反向删除操作 , 所以链表当中的节点上也需要记录下Key值 , 否则的话删除就没办法了 。 删除之后再加入新的节点 , 这个都很简单:
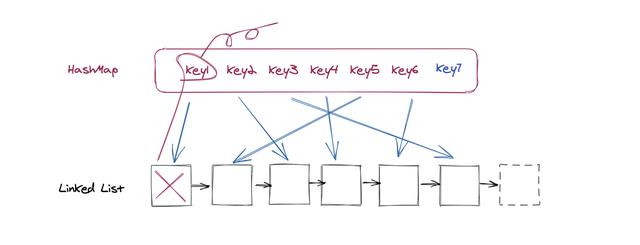 文章插图
文章插图我们理顺了整个过程之后来看代码:
class Node:def __init__(self, key, val, prev=None, succ=None):self.key = keyself.val = val# 前驱self.prev = prev# 后继self.succ = succdef __repr__(self):return str(self.val)class LinkedList:def __init__(self):self.head = Node(None, 'header')self.tail = Node(None, 'tail')self.head.succ = self.tailself.tail.prev = self.headdef append(self, node):# 将node节点添加在链表尾部prev = self.tail.prevnode.prev = prevnode.succ = prev.succprev.succ = nodenode.succ.prev = nodedef delete(self, node):# 删除节点prev = node.prevsucc = node.succsucc.prev, prev.succ = prev, succdef get_head(self):# 返回第一个节点return self.head.succclass LRU:def __init__(self, cap=100):# cap即capacity , 容量self.cap = capself.cache = {}self.linked_list = LinkedList()def get(self, key):if key not in self.cache:return Noneself.put_recently(key)return self.cache[key]def put_recently(self, key):# 把节点更新到链表尾部node = self.cache[key]self.linked_list.delete(node)self.linked_list.append(node)def put(self, key, value):# 能查到的话先删除原数据再更新if key in self.cache:self.linked_list.delete(self.cache[key])self.cache[key] = Node(key, value)self.linked_list.append(self.cache[key])returnif len(self.cache) >= self.cap:# 如果容量已经满了 , 删除最旧的节点node = self.linked_list.get_head()self.linked_list.delete(node)del self.cache[node.key]u = Node(key, value)self.linked_list.append(u)self.cache[key] = u
- 雷军:2021年的第一件大事,给工程师发百万美金大奖
- 日本工程师:潘多拉魔盒被美国打开,中国办芯片大学只为打破禁令
- 性能翻倍!飞腾首款8核桌面处理器腾锐D2000详解
- 从工程师到“水果猎人”他在百度做科普
- 年代感十足!前苹果工程师放出初代iPhone生产线照片
- 能装进口袋的工程师运维笔记本:壹号本壹号工程师PC A1
- 布局AI药物研发!华为招聘药物研发算法工程师,早有准备进军医疗行业?
- 网速再翻倍,官方详解小米 11 搭载的 WiFi 6 增强版技术
- 腾讯数据工程师推荐的Python新手入门书籍,还是首发电子版
- 美国工程师:中国又一项技术刷新纪录!科技史上又一里程碑的存在